Memory leaks happen when a program fails to release memory it no longer needs, and can be a big issue for developers and system administrators alike, as the gradual depletion of available memory often makes for complex troubleshooting and debugging. Given how the consequences of a memory leak can range from decreased system performance to outright crashes, it’s crucial to isolate the root cause of the leak quickly and efficiently. This post covers how to isolate memory leaks with production traffic replication, a technique that uses traffic replay and automatic mocks to test services in isolation. This post also discusses common mistakes to avoid when troubleshooting memory leaks, such as not isolating the service from other services, not finding the root cause, and assuming memory leaks are solely in the code. By the end of this guide, you’ll have a better understanding of how to identify and isolate memory leaks in your Kubernetes environment.
What Are the Causes of Memory Leaks?
Memory leaks can happen due to programming errors, poorly written algorithms, or resource-intensive processes. As available memory depletes over time, the system’s performance suffers, causing increased load times and bad user experiences. This can cause long-term tack on effects across the entire stack, and when one device stops working correctly, this can compound into further memory leaks or complimentary pressures in the system. often, what caused memory issues in the first place is not super impactful in isolation - it is rather the sum total of all impacts that adds up to something quite significant. Especially in complex systems like Kubernetes where multiple processes run simultaneously, isolating memory leaks can be challenging for developers. However, doing so is crucial as memory leaks can cause issues outside of performance, potentially playing a role in cyber attacks. Issues of this nature can compound in systems using dynamic memory allocation such as heap memory - to use one of many liquid based analogies, if you have pipes that take in variable amounts of water, and you dump thousands of gallons into a single pipe randomly, the system will fail regardless of how good the secondary measures or overflow systems are - no system in the world can take that kind of pressure shock well.  ALT: Piping and other liquid based analogies are often used to provide context for memory leaks, expressing data as water and the system which carry that data as pipes. Imagine this: when clearing a cart on your webshop you send a request to the backend formatted as /cart/delete/{id}. When called, the API will look up the ID and any associated products. But in this scenario, there’s a bug—a request with an invalid ID will cause the API to search through all carts and throw an exception when the cart isn’t found. Now, all the cart IDs aren’t cleared in memory because of the exception. Not only is this bad for performance and infrastructure cost, but a malicious actor may discover this and use it to cause a DDoS attack, possibly doing it gradually so as to not trigger any alerts. This can result in lost traffic and revenue, but can also allow attackers to create huge distractions for file exfiltration, computer system infiltration, or much worse.
ALT: Piping and other liquid based analogies are often used to provide context for memory leaks, expressing data as water and the system which carry that data as pipes. Imagine this: when clearing a cart on your webshop you send a request to the backend formatted as /cart/delete/{id}. When called, the API will look up the ID and any associated products. But in this scenario, there’s a bug—a request with an invalid ID will cause the API to search through all carts and throw an exception when the cart isn’t found. Now, all the cart IDs aren’t cleared in memory because of the exception. Not only is this bad for performance and infrastructure cost, but a malicious actor may discover this and use it to cause a DDoS attack, possibly doing it gradually so as to not trigger any alerts. This can result in lost traffic and revenue, but can also allow attackers to create huge distractions for file exfiltration, computer system infiltration, or much worse.
How to Detect Memory Leaks
Production traffic replication is a technique that uses traffic replay and automatic mocks to isolate a service under testing, providing a realistic environment for performance testing. Deeper dives can be found in other posts like the definitive guide to traffic replay or the advantages of mock APIs. This guide shows how to use Speedscale—a Kubernetes-specific tool based on production traffic replication—to isolate memory leaks with real-world traffic. The steps below assume an existing Speedscale installation. If you’ve yet to set one up, check out the complete traffic replay tutorial to get started. You can also follow along with some parts in the interactive demo.
Infrastructure or API?
Determining whether the memory leak is caused by your infrastructure or your API itself, is the very first step. To do this, run a simple load test using traffic you’ve recorded from production. Specific instructions for this can be found in the load testing tutorial, but essentially you’ll be using the speedctl CLI to spin up a new application instance in your development cluster, generate load towards said instance, then provide a report with collected metrics. The below screenshot is from an example report found in the interactive demo. 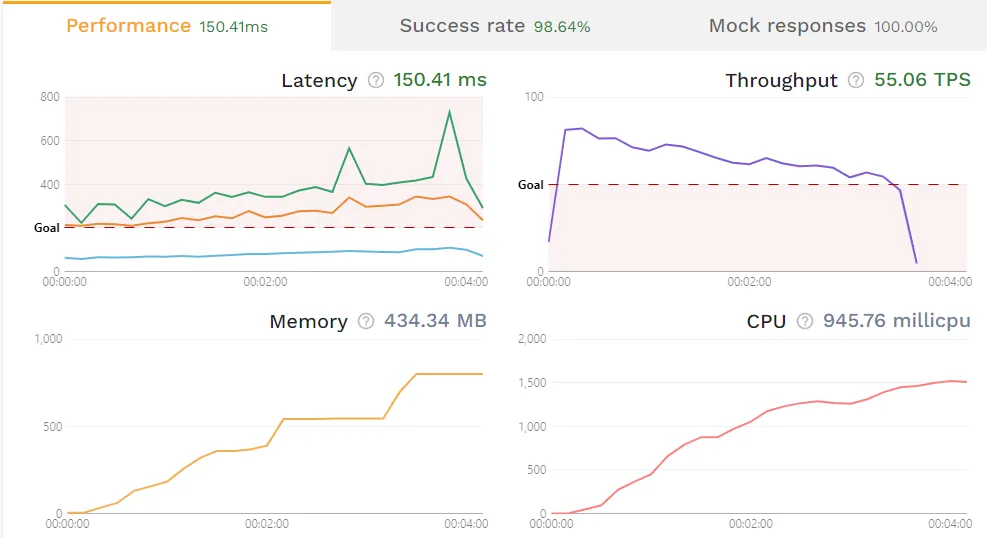 This application may have a memory leak issue, given how the usage never decreases. That said, it’s crucial that you understand and replicate your application’s ramp patterns accurately. Failing to do so may cause incorrect results or false positives. The test above took under 5 minutes, so the rising usage may simply be because of a long-running task, or garbage collection not having run yet. This initial step involves identifying whether the memory leak is a result of the Service-under-Test (SUT) or if it is due to improper infrastructure configurations, such as a mismanaged garbage collector. If this simple load test isn’t generating a memory leak, it’s highly likely that your memory leak stems from your infrastructure or other production-specific configurations, rather than your application. In other words, if a simulation that mirrors real-world usage does not cause a memory leak, you’re likely not testing the actual source of the leak.
This application may have a memory leak issue, given how the usage never decreases. That said, it’s crucial that you understand and replicate your application’s ramp patterns accurately. Failing to do so may cause incorrect results or false positives. The test above took under 5 minutes, so the rising usage may simply be because of a long-running task, or garbage collection not having run yet. This initial step involves identifying whether the memory leak is a result of the Service-under-Test (SUT) or if it is due to improper infrastructure configurations, such as a mismanaged garbage collector. If this simple load test isn’t generating a memory leak, it’s highly likely that your memory leak stems from your infrastructure or other production-specific configurations, rather than your application. In other words, if a simulation that mirrors real-world usage does not cause a memory leak, you’re likely not testing the actual source of the leak.
Dissecting the API
If the above did indeed produce a memory leak, there’s a higher chance of the leak occurring from within the application itself. These next steps help you determine exactly what part or parts of your application causes the leak. Run your load test again, this time removing all traffic to endpoint A. If the leak still occurs, remove all traffic to endpoint B instead. Continue stripping the load test of traffic until you’ve found the endpoint where the leak occurs. Especially in organizations where different teams are responsible for different endpoints, this can help delegate the task to the right owner. With the problematic endpoint determined, you can now remove variations in requests one by one. For instance, remove all traffic sent from Chrome, remove all traffic sent from desktop, etc. This is where the true power of production traffic replay comes in handy. Consider once again the /cart/delete/{id} example from earlier, how would you isolate that without real-world traffic? There are a variety of factors required to make that memory leak happen:
- Real-world behavior: Other carts need to have been created that the API looks up.
- Unexpected API input: The bug is triggered by an invalid cart ID.
- Suboptimal dependencies: It’s easily argued how the cart API shouldn’t even be looking through other cart IDs in the first place, instead just sending a delete request to the database. But, issues like this can often happen when inexperienced engineers use ORMs to handle database transactions.
- Ramp patterns: Memory leaks often happen over time as opposed to instantly. An issue like this is unlikely to be found with a 2-minute load test.
Now, could you replicate all of these factors manually? Possibly. Would you think to do it? It’s unlikely. Would you have the time to replicate them? Most likely not. In many ways, production traffic replication doesn’t enable scenarios that are impossible to create manually. Rather, it makes them viable.
Mistakes to Avoid When Troubleshooting Memory Leaks
During troubleshooting, there are a number of common mistakes that can hinder the isolation process. Not isolating the service from other services is likely the most common mistake as it requires solid mock servers to be truly avoided. Not finding the root cause and/or most optimal solution often happens when the consequences of a memory leak are severe and need to be limited immediately—like, setting aggressive resource limits. A good short-term solution, but don’t forget to keep digging. Assuming memory leaks are in the code happens as it’s true most of the time, but not always. Not using proper monitoring tools will significantly reduce your ability to quickly isolate and fix a memory leak. A simple kubectl top may reveal the problematic Pod, but won’t tell you anything about why it’s happening. Not testing old bugs won’t necessarily cause issues, which is exactly why it’s dangerous. Continuing the cart API example: you may have fixed the error handling, but how do you know it won’t break again? It’s highly recommended to implement regression testing, which—thanks to production traffic replication—is now possible even for performance.
How to Fix Memory Leaks
Identifying and isolating memory leaks in complex systems like Kubernetes can be a daunting challenge for developers, but it’s crucial to maintain optimal system performance and prevent cyber attacks. Using production traffic replication tools like Speedscale can make this process much more manageable and effective. By running load tests and utilizing the exclusion method, developers can identify the root cause of memory leaks and ensure proper isolation. Additionally, avoiding common mistakes and employing proper monitoring tools can go a long way in preventing the recurrence of previously fixed bugs. It’s important to note as well that memory leaks are notoriously hard to prevent, as they often require longer soak/smoke tests to reveal. Once again, it’s crucial that you understand and replicate your unique ramp patterns, like a European B2B SaaS company experiencing spike traffic around 8-9am on weekdays, then sustained traffic until 4-5pm. Moreover, the cart example from earlier showcases how memory leaks are often transient, only happening in very specific scenarios. Production traffic can help isolate and find those errors when they occur, but preparing for them requires you to implement some form of chaos testing. For example by instructing mocks to return high response times or bad status codes X% of the time.  Whatever your approach will look like, I recommend integrating performance testing continuously. There are many ways of implementing it, for example—running a quick load test on pull requests to feature branches, then running longer soak tests during deployment. Or, you may want to replay traffic during development with preview environments.
Whatever your approach will look like, I recommend integrating performance testing continuously. There are many ways of implementing it, for example—running a quick load test on pull requests to feature branches, then running longer soak tests during deployment. Or, you may want to replay traffic during development with preview environments.
Examples of Memory Leaks
Memory leaks can have some significant impacts on a service and the data it contains. Below are just a few examples of what a memory leak can look like and how detrimental it can be for the service.
Large Object Caching Without Eviction
When large objects are stored in memory, this content is held until a specific event or threshold is reached. When this barrier is reached, eviction of the data occurs, freeing up resources. When poor eviction policy management is in place and explicit deallocation is not implemented, this data can result in massively bloated resources due to over allocated memory. Even when the system deploys dynamic memory allocation, this can result in significant data bloat, reducing the efficiency of running code. As this inefficiency piles up and restricts the allocation of new memory, the system slows - and in some cases, the program terminates.
Unclosed Database Connections
This type of memory leak is fairly hazardous, and can cause significant issues over time. When APIs connect to a database but fail to close the connection after their running jobs are over, these database connections remain open. This can result in connections with an indefinite life limit, resulting in a decay in proper operation and eventual denial of connection for new sources. Over time, this can result in a heap of other problems beyond just failed connections, including security vulnerabilities, uncontrolled access points, and even full-on application failure. This may seem a trivial example, but when paired issues in dynamically allocated memory, incomplete systems to manage memory, and open database connections, your best case scenario is slow down - and your worst case scenario is when your application fails completely and regularly without any obvious reason.
Inappropriate Static References
Using static variables to hold data that accumulates over time without releasing these references can result in huge memory usage, eventually resulting in indefinite compounding growth as more and more users login. This can result in decaying system performance, but even when the amount of data is small, can result in low data availability for other users. This can result in dramatic impacts such as program termination, but can also result in smaller issues such as failed calls, slow data return, and other issues which are hard to track down unless you know what you’re looking for. While your memory allocation with eventually run out, the time before that will be just as impactful, if not as obvious.
Unbounded Data Parsing
Unbounded data parsing is when APIs process JSON or XML payloads with minimal or absent limits. This can lead to significantly excessive memory consumption, and can also open up new vulnerabilities to security injections. For example, if an API accepts arbitrarily large JSON inputs and keeps them in memory for parsing, this can cause OutOfMemoryErrors during high traffic, impacting the core system while reducing the memory for other programs. In many cases, this problem also comes with poor sanitization, as it points to a bad understanding of the data flow.
Circular References in Serialization/Deserialization
Serialization libraries (e.g., Jackson, Gson) may encounter circular references in complex objects, resulting in significant memory leaks. If an API serializes objects with bidirectional references - without configuring proper handling - objects may stay in memory longer than needed. In many cases this introduces simple resource bloat, but it can also cause significant downstream errors in resolution, especially since it may be unclear where the data in memory originated.
Conclusion
Ultimately, discovering where and how a memory leak occurs comes down to effectively implementing best practices for the management of system memory alongside adopting trusted tools from strong third parties. Program code should never be a static thing - very old systems always need to be updated, new users have new demands on the underlying platforms, and so forth. So why should memory management be any different? Consider memory management to be an ongoing concern that requires constant attention and auditing, and you can make a more secure system that is more effective, cheaper to run, and more aligned to your end user.  If you’re interested in using traffic replay in your memory leak prevention and management systems, check out Speedscale! You can get started with a free trial today!
If you’re interested in using traffic replay in your memory leak prevention and management systems, check out Speedscale! You can get started with a free trial today!