
In the last post we covered the industry shift towards ARM machines for both local and production software engineering. Last time we learned how to create Docker images that would work on multiple architectures for dev machines. Now we want to take this portability and leverage it for cost savings in production. You may be able to transition some of your services into multi-architecture builds. In reality, you will have some legacy services that can’t transition or some workloads in your cluster that do not support ARM yet. For Speedscale, we transitioned all our in house services. But we still have a few cluster utilities that don’t have ARM support yet so we can’t just run all ARM nodes. Luckily, Kubernetes is built to support multiple node types and has mechanisms to make sure your workload gets scheduled on the right node type.
Note that this guide is specifically for Kubernetes and even more specifically EKS on AWS. The general concepts will be the same regardless of cloud provider since Kubernetes has support for different node types but the specifics of how to configure your nodes will vary. So let’s get right into it!
Set up an ARM node group in EKS
Go to your cluster and under Compute find your node groups. Click Add Node Group.
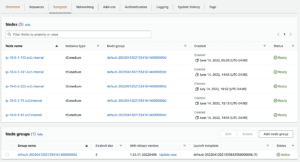
Configure this node group with the same properties as your other one. Click Add Taint.
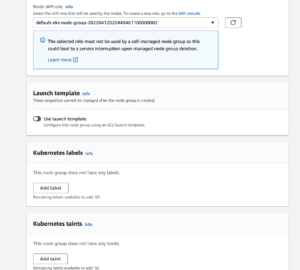
Add a taint with the key arch and value arm.
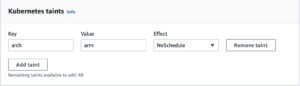
Select an ARM compatible AMI (Amazon Linux and Bottlerocket both support ARM). Select your preferred instance types. The AWS UI is smart enough to suggest ARM instances when you select your AMI.
Continue through the rest of the wizard with the same networking settings as your other node group.
This is everything you’ll need to do on the infrastructure side. Creating a node group can take anywhere from 5-20 mins, so in the meantime, we’ll update our Kubernetes manifests to use this new node group.
Update Kubernetes manifests
Here is an example deployment manifest
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: demo
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.22.0
resources:
requests:
cpu: 100m
memory: 56k
limits:
cpu: "1"
memory: 512M
volumeMounts:
- mountPath: /etc/nginx/conf.d/ # mount nginx-conf volumn to /etc/nginx
readOnly: true
name: nginx-conf
ports:
- containerPort: 8080
volumes:
- name: nginx-conf
configMap:
name: nginx-conf
items:
- key: custom.conf
path: custom.confWe’re going to add a toleration and a nodeSelector to this manifest, shown below. The example here is a deployment but any manifest involving containers can specify these blocks such as a Job , CronJob , StatefulSet , etc.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: demo
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- key: "arch"
operator: "Equal"
value: "arm"
nodeSelector:
kubernetes.io/arch: arm64
containers:
- name: nginx
image: nginx:1.22.0
resources:
requests:
cpu: 100m
memory: 56k
limits:
cpu: "1"
memory: 512M
volumeMounts:
- mountPath: /etc/nginx/conf.d/ # mount nginx-conf volumn to /etc/nginx
readOnly: true
name: nginx-conf
ports:
- containerPort: 8080
volumes:
- name: nginx-conf
configMap:
name: nginx-conf
items:
- key: custom.conf
path: custom.confThat’s it! So let’s get into what we did here.
Kubernetes Scheduling
The Kubernetes Scheduler is one of the meatiest parts of the platform. There are many things going on behind the scenes that determine where a pod gets created and why. For our use case, we specifically use the taints and tolerations feature of the scheduler to ensure non-ARM workloads don’t get scheduled onto ARM nodes.
Taints and Tolerations
Taints mark a node as having a property that prevents pods being scheduled on it unless the pod specifically says it’s ok with the taint. The pod specifies this with a Toleration. In our case, our node was tainted with arch=arm and the action of NoSchedule . We could have used any key value pair here with the same action. This ensures nothing gets scheduled on the nodes by default. We specified a toleration via the block below where we matched on the key and value and did not specify a particular action which indicates we match all actions.
tolerations:
- key: "arch"
operator: "Equal"
value: "arm"Node Selectors
We also used the nodeSelector property in our manifest. This specifically says to only schedule this workload on nodes that match the label we specified. We use kubernetes.io/arch: arm64 for our label which is one of many default labels applied by Kubernetes. We could choose not to specify this nodeSelector property since we know our workload works on multiple architectures. In that case the scheduler would schedule the pod on any node in the cluster instead of specifically targeting arm64 ones. This is a useful pattern for things like Jobs and CronJobs since we can use whatever node has some overhead instead of being bound to a single type of node.
Autoscaling
If you have use the Kubernetes Autoscaler , it takes all these scheduling constraints into consideration when determining which nodes it needs to scale up or down. This means no changes are needed to the autoscaling configuration with this new node group. All these new taints, tolerations and node selectors.
Recap
We added an ARM node group to an existing cluster and put taints on it to prevent any unintentional workload scheduling. Then we modified our manifests to tolerate these taints and used a node selector to explicitly always schedule on these ARM nodes. These simple steps will enable you to save up to 40% on your compute costs based on your instance types and the number of workloads you can move over to the ARM nodes. For us at Speedscale, it’s reduced our EC2 costs by about 32% and possibly more in the future when we can transition some of our external dependencies.
But I don’t use EKS!
Google Cloud recently announced it was adding ARM instances to its offerings and Azure has these as well, both of which are cheaper than non-ARM instances. Regardless of cloud provider, you should be able to set up multiple node types for your cluster, for eg. node groups are called node pools in GKE and Azure. All the concepts mentioned above are purely Kubernetes constructs so they should apply to all Kubernetes clusters
Downsides
The only real downside here is having to manage multiple node groups which have different AMIs. This means any updates to the AMI will have to be rolled out to each group individually. There is also the increased time to build the container images since we are effectively building two images in parallel but the cost benefits greatly outweigh these minor inconveniences.
These steps should help you reduce your cost by switching to ARM instances and can also be used in general to set up multiple node groups. Different node groups for GPU instances or some other special workload can be set up in this way.