TL;DR
Software testing is an integral part of software development. However, validating edge cases, corner cases, and non-happy paths often get overlooked. Testing these sorts of scenarios is a crucial step in ensuring the resilience of applications.
By effectively responding to unexpected conditions and preventing the entire system from crashing, users will either be blissfully unaware that an error has occurred, or at the very least, you have a chance of providing a useful error message.
This post covers these concepts, highlighting their importance in software testing. We’ll also focus on a powerful technique for validating these cases: production traffic replication (PTR).
Kubernetes Auto-Scaling: A Real-World Example
To illustrate the importance of validating edge cases, let’s consider a real-world application commonly deployed in Kubernetes, with the following characteristics:
- Online book store: Experiences large amounts of traffic during holiday seasons and marketing campaigns
- Microservice architecture: Separate services for authentication, products, shopping cart, and payment processing
- Auto-scaling: Scales up and down based on CPU usage, as the services are not memory-intensive
This application is designed to handle a certain amount of traffic. When the traffic volume increases beyond a certain threshold, Kubernetes auto-scaling feature kicks in, creating additional pods to handle the increased load.
During regular operation, the application experiences a steady stream of traffic, with occasional spikes during peak usage times. Under normal circumstances, this allows the application to handle traffic spikes smoothly, ensuring a consistent user experience.
Edge Cases and Corner Cases: A Deep Dive
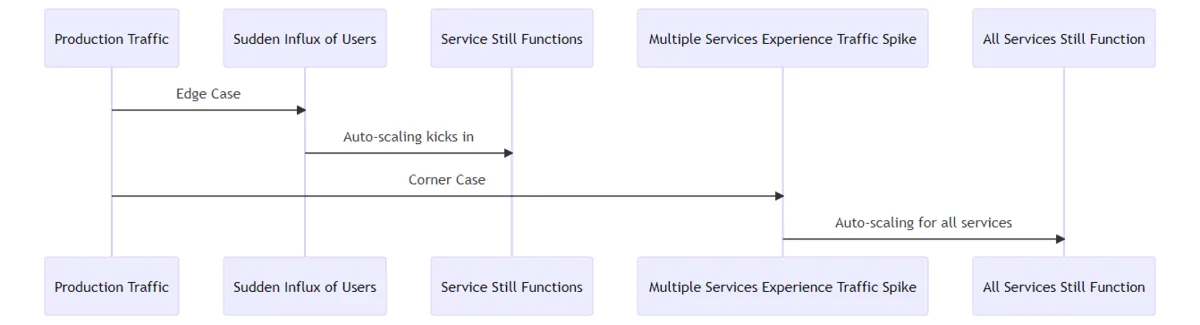
An edge case is when an application experiences use cases at the very edge of its capabilities. For instance, a sudden influx of users due to a viral social media post about a book sale, generating enough traffic where the service still functions, but the auto-scaling configuration doesn’t allow any more Pods.
A corner case is a situation where multiple edge cases occur at the same time. For our application this would be when multiple services experience a sudden spike in traffic simultaneously, triggering auto-scaling for all of them. For example, a simultaneous increase in user logins, book searches, and payment transactions due to a site-wide discount event.
To validate these edge and corner cases, replaying a large volume of traffic in a short period in our non-production environment, lets us observe how our application and the auto-scaling feature respond. This allows us to ensure that auto-scaling kicks in as expected and that the application can handle the increased load.
Non-Happy Paths and Boundary Value Analysis
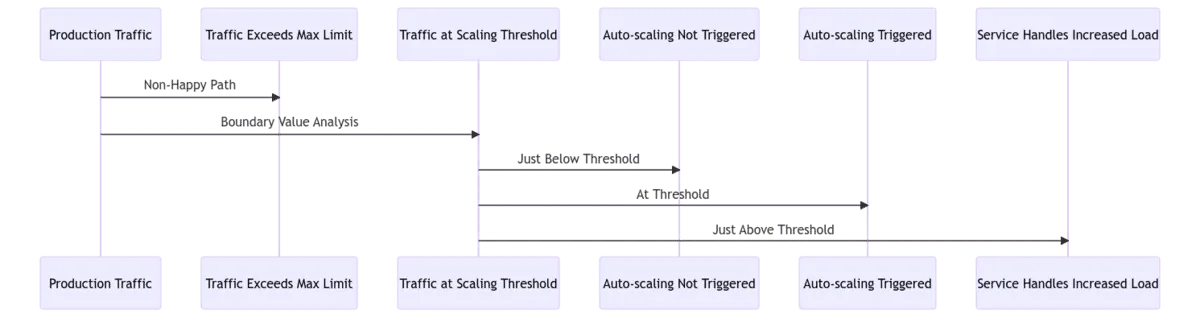
A non-happy path for our application would be a traffic spike so large that it exceeds the maximum scaling limit; something we weren’t prepared for. For instance, a sudden surge in traffic due to a global event like World Book Day.
For boundary value analysis, we would look at traffic volumes that are just below, at, and just above the threshold that triggers auto-scaling, as they’re at the edges of an input range that causes a change in the application’s behavior.
Replaying traffic at these volumes in our non-production environment, we can observe how our application and the auto-scaling feature respond. This allows us to ensure that auto-scaling triggers at the correct traffic volume and that the application can handle traffic volumes slightly above the maximum scaling limit.
Code Coverage, the Pareto Principle, and Comprehensive Testing
Code coverage quantifies the extent of your testing by measuring how much of your codebase is covered by your test cases, and is a great indicator of how much testing is being done, while also pinpointing areas that need additional testing.
With our online bookstore application, code coverage helps us identify which parts of the auto-scaling feature are adequately tested and which parts need more attention. For instance, we might discover that our tests cover the scenario where traffic gradually increases but not where it spikes suddenly due to a flash sale.
The Pareto Principle—also known as the 80/20 rule—asserts that “for many outcomes, approximately 80% of consequences come from 20% of the causes”, often interpreted as “80% of all bugs can be found in 20% of program modules”.
Applying the Pareto Principle to our online bookstore, we might find that 80% of issues arise from 20% of the services like the payment processing or the book listing service. The cause of this can be plenty, e.g. these services being more complex or having more dependencies, making them more prone to errors.
Incorporating Edge Case Validation into the Software Development Process
Edge case validation is not just a one-off task, but a continuous process that should be integrated into your software development lifecycle, so you can catch potential issues early and reduce the risk of bugs making it to production. Ultimately, delivering a more robust and reliable application.
Incorporating edge case validation into your CI/CD pipeline, you catch potential issues early and prevent them from making it to production, by continuously testing against edge cases as new code is integrated.
Traditionally, this would require regular reviews of the edge case tests, updating them as new code is added and new features are deployed. While tests generated from production traffic may not cover 100% of test cases, it’s a way to at least cover the use cases you’re actually experiencing in production. And in any case, you’ll likely find the use of PTR to be much more time-efficient and comprehensive than conventional scripting.