Data & Traffic Are Key to Kubernetes Preview Environments
Preview environments are temporary environments where developers can test code changes before deploying them to production, also called ephemeral environments, they’re temporary and should be discarded after testing changes. Carrying out tests using accurate data is a major challenge when creating and destroying environments. Put differently, you need realistic data and traffic in the preview environment to reflect the performance of code changes in production. Imagine you’re developing a recommendation engine for an e-commerce website where you work on the layer between the user and the engine. You must properly package and parse the engine’s output because it uses different factors—like the user’s behavior, past purchases, etc.—which you should pass to the engine. To do this, you need test data from the user and the engine. But how do you ensure the availability of the data after spinning an ephemeral environment? Using a centralized development database defeats the purpose of using preview environments. But loading all the test data into your local environment requires a lot of resources. Also, it’s complicated to create and maintain test data considering the importance of realism in testing. Using user traffic, which will be covered alongside the importance of data in preview environments, is one way of solving the test data issue.
Simulating Production With Real Data
Simulating the behavior of production as closely as possible is a key component of a successful Kubernetes environment. This includes the code running within the environment and the various data sources and user traffic that interact with the application. In this context, data isn’t a single entity or a point. Instead, data in preview environments can contain third-party APIs and database transactions. Proper handling and test data consideration are essential to the success of preview environments, especially in terms of avoiding permanent alteration and impact on other people’s testing or using realistic data. Considering the effort involved and the usefulness of tests performed in preview environments, data is the biggest challenge of setting up preview environments. Any test environment that’s not based on realistic data will fall short. Looking back at the example from the introduction, an optimal preview environment will contain a mock server simulating responses from the recommendation engine. This will increase the efficiency of development because it doesn’t require dependencies. However, what happens if the simulated responses aren’t exact replicas of the real API? You run the risk of errors occurring in production, including the ones you tested for in the preview environment but didn’t catch because the mock server is outdated or poorly configured. The same thing happens if the user data you’re using doesn’t match production. To ensure applications run as an isolated unit, many focus on implementing coding paradigms like 12-factor apps. Although data determines the quality of insight you’ll get, it doesn’t get the same attention.
The Role of User Traffic in Preview Environments
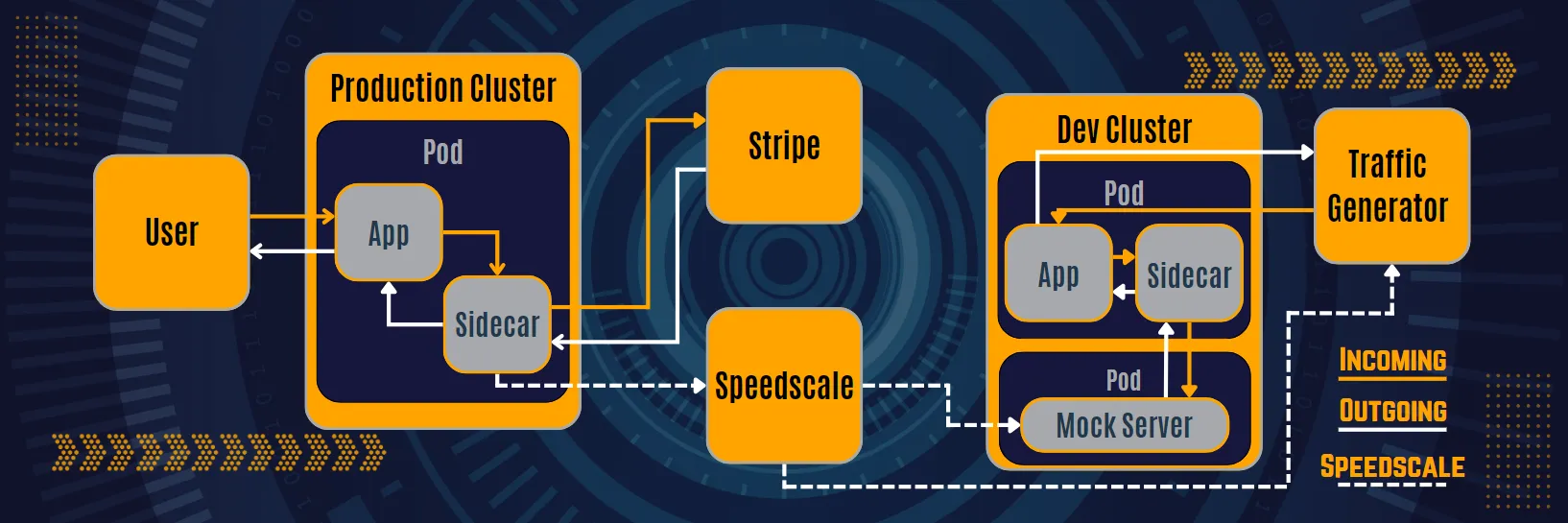 Preview environments replicate the sort of usage the application experiences. It’s the same reason automated UI testing exists—it’s not enough to manually click around an interface. As products get complex, it’s less and less accurate to test the functionalities and performances of applications manually. As a result, many organizations use tools like Postman to generate collections of API requests that can test most parts of an application. However, manual test cases don’t fully replicate the user’s behavior, which is the ultimate goal of testing. Additionally, manually generating API requests for all paths (and all variations of paths) is time-consuming. Combine that with how users may interact with your application in ways you didn’t expect—which you can generate a request for—and manually generating test cases should be off the table. Using realistic data is the only way to get accurate insights from your preview environment. And using real data recorded from your environment is the only way to get realistic data. This is true for incoming and outgoing requests. When recording user traffic, you’ll get the request path and body. You’ll also receive headers, timing between requests, and everything included in a real user interaction. Recording user data isn’t as easy as setting up a packet sniffer and storing everything that’s captured. Regulations like GDPR impact the user data you can capture and store. For example, Personally Identifiable Information (PII) is off limits, which includes data like a user’s IP. Although recorded user traffic is the only way to create realistic preview environments, it has unique challenges like international regulations. But tools like Speedscale account for all these factors in its system, allowing you to focus on the _use _of preview environments rather than the implementation.
Preview environments replicate the sort of usage the application experiences. It’s the same reason automated UI testing exists—it’s not enough to manually click around an interface. As products get complex, it’s less and less accurate to test the functionalities and performances of applications manually. As a result, many organizations use tools like Postman to generate collections of API requests that can test most parts of an application. However, manual test cases don’t fully replicate the user’s behavior, which is the ultimate goal of testing. Additionally, manually generating API requests for all paths (and all variations of paths) is time-consuming. Combine that with how users may interact with your application in ways you didn’t expect—which you can generate a request for—and manually generating test cases should be off the table. Using realistic data is the only way to get accurate insights from your preview environment. And using real data recorded from your environment is the only way to get realistic data. This is true for incoming and outgoing requests. When recording user traffic, you’ll get the request path and body. You’ll also receive headers, timing between requests, and everything included in a real user interaction. Recording user data isn’t as easy as setting up a packet sniffer and storing everything that’s captured. Regulations like GDPR impact the user data you can capture and store. For example, Personally Identifiable Information (PII) is off limits, which includes data like a user’s IP. Although recorded user traffic is the only way to create realistic preview environments, it has unique challenges like international regulations. But tools like Speedscale account for all these factors in its system, allowing you to focus on the _use _of preview environments rather than the implementation.
The Benefits of Mocking Backends Automatically
Now, the importance of keeping test data up-to-date is clear. While it’s easy to replay recorded user traffic against your application, don’t underestimate the power of recording outgoing requests. After recording the response from the recommendation engine, storing it in a centralized location is a great way to keep the updated data available. And, true power comes from using the data to automatically create your mock server. But automatic mock creation has some challenges, just the same way you can’t capture network packets for incoming traffic. For example, how do you handle different technologies like gRPC, Postgres, HTTP/2, etc.? This is another example where a third-party tool like Speedscale, which can automatically detect and simulate different technologies, allows you to focus on the use rather than the implementation. So, how does Speedscale work? At a high level, Speedscale uses your recorded traffic to configure a mock server. Then, your outgoing requests are rerouted to the mock server by the sidecar proxy that’s installed when you set up Speedscale. This means you don’t need to set up or maintain external services. It’s crucial to maintain updated mocks, and the automatic creation of mocks makes this possible without any human interaction. This is an invaluable feature because some companies discovered that mock maintenance costs 10x the effort it takes to implement a feature. And this is just one advantage of using Mock APIs in development.
The Need to Seed Data Properly
Preview environments should replicate production as closely as possible. Seeding data—incoming and outgoing—is crucial to achieving this goal. If developers can achieve this, they can gain more realistic and meaningful insights from testing. The approach to seeding data impacts the possibilities of Kubernetes preview environments. For instance, using production traffic replication—the combination of traffic replay and automatic mocks— allows developers to easily integrate preview environments into CI/CD pipelines. After ensuring realism in your test data, add automation. Manually clicking a button to seed the data might seem insignificant, but what happens if you forget the steps? Is there a risk of using outdated data? You should also consider how the process impacts the developer’s experience. For instance, seeding that takes minutes to complete may break the flow of a developer, leading to reduced efficiency. Finally, reading and learning about new concepts is one thing; practicing them is another. To know what it takes, read the tutorial on how to create a Kubernetes preview environment.