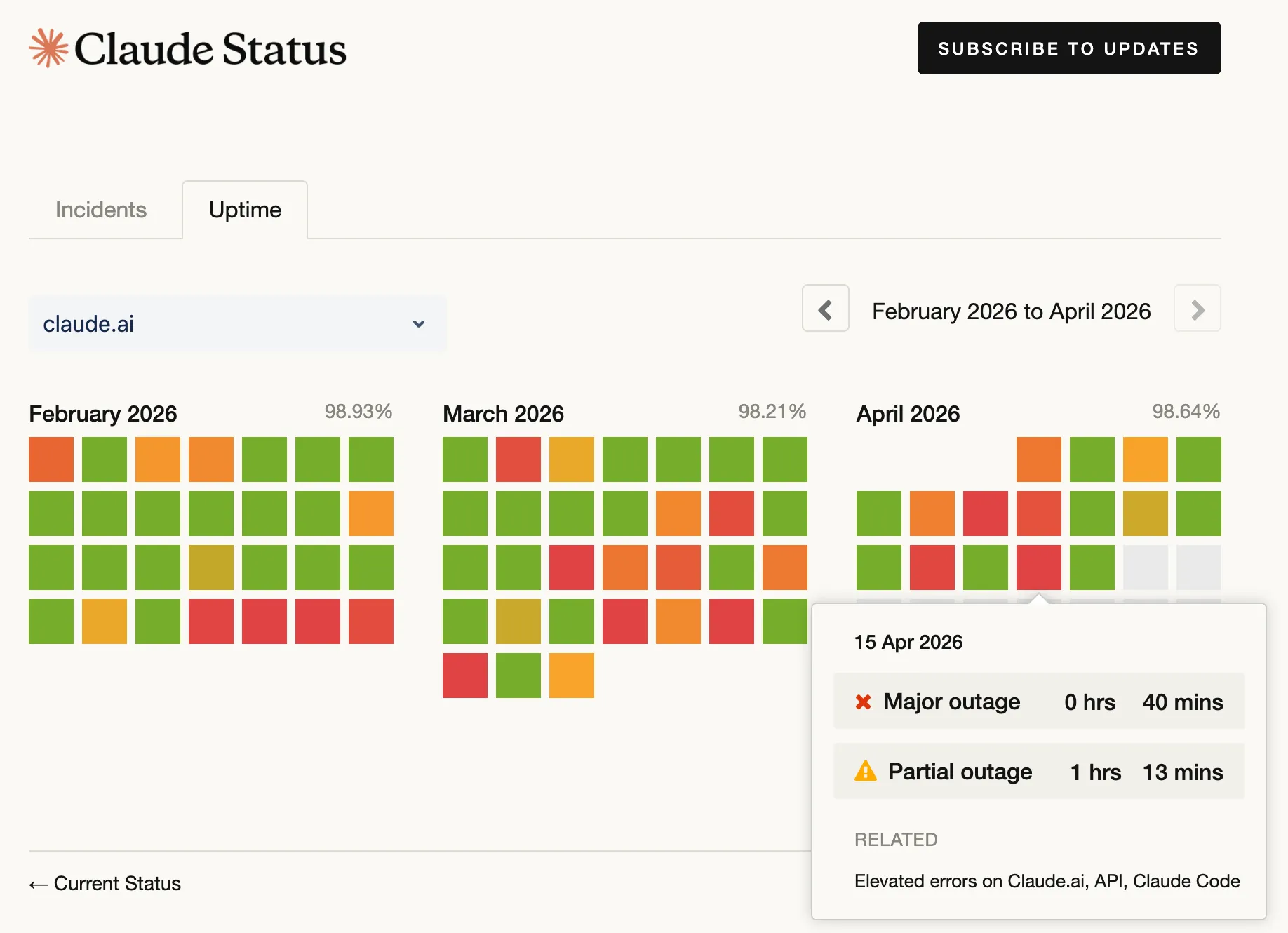
Beyond AI Vibes: Deterministic Foundations for Agentic Coding
Every week there is another model drop, another agent framework, and another workflow tweak you are supposed to evaluate. Meanwhile, the largest companies, the ones operating at the highest scale and leaning hardest on AI, are also the ones making headlines for reliability strain: capacity limits, outages, and services that buckle under load.
If the organizations with the most AI investment are struggling, the problem is not “more AI.” The problem is speed without proof: changes that move faster than the systems that validate them.
Adoption is up; confidence is not
Pull request volume is climbing. Teammates ship refactors, experiments, and feature branches at a pace that would have felt impossible a few years ago.
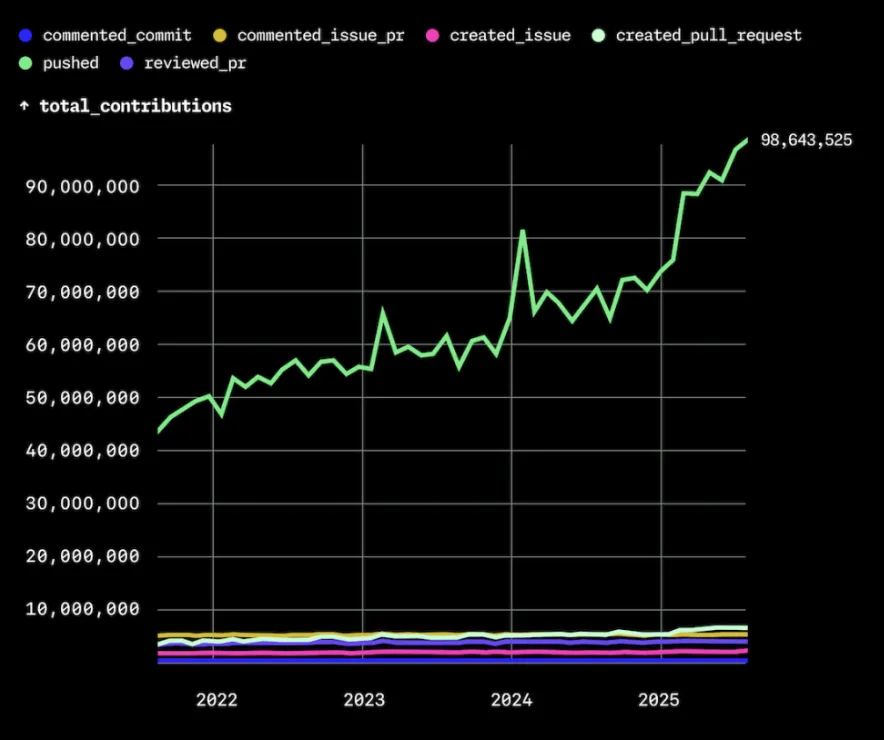
Industry surveys paint a consistent picture. The 2025 Stack Overflow Developer Survey reports AI coding tool usage is now mainstream while self-reported trust in AI-generated output has dropped year over year. Developers are not rejecting assistants. They are using them while remaining skeptical of what comes back.
That gap matters because “accepted in the IDE” is not the same as “safe in production.”
What the telemetry actually says
This is not a vibes argument. Engineering analytics firms have started publishing hard metrics from version control, CI, and incident systems: telemetry that measures what shipped, what broke, and how much rework followed.
Faros AI’s research on AI’s engineering impact, for example, tracks organizations across periods of low versus high AI adoption. One finding stands out: code churn, the ratio of deleted lines to added lines in merged work, can spike dramatically as teams iterate with AI assistance, because the same surfaces get rewritten repeatedly while people chase correctness.

Separately, a study by Coderabbit reports rising defect rates and more production incidents per merged change as adoption increases. Not because AI is useless, but because throughput grew faster than the validation systems around it.
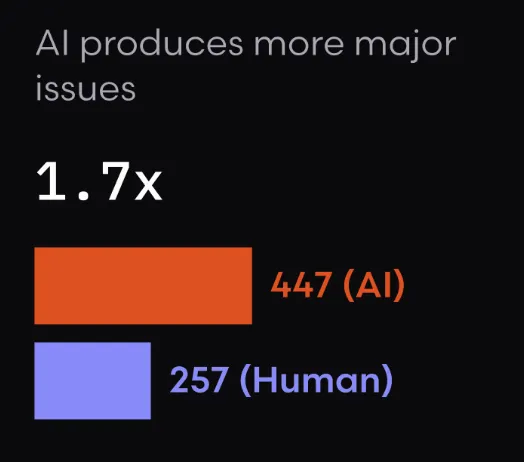
Review is where the pain shows up in human time. Faros reports large increases in time spent in code review as volume grows and AI-generated changes look plausible at a glance but hide subtle failures.
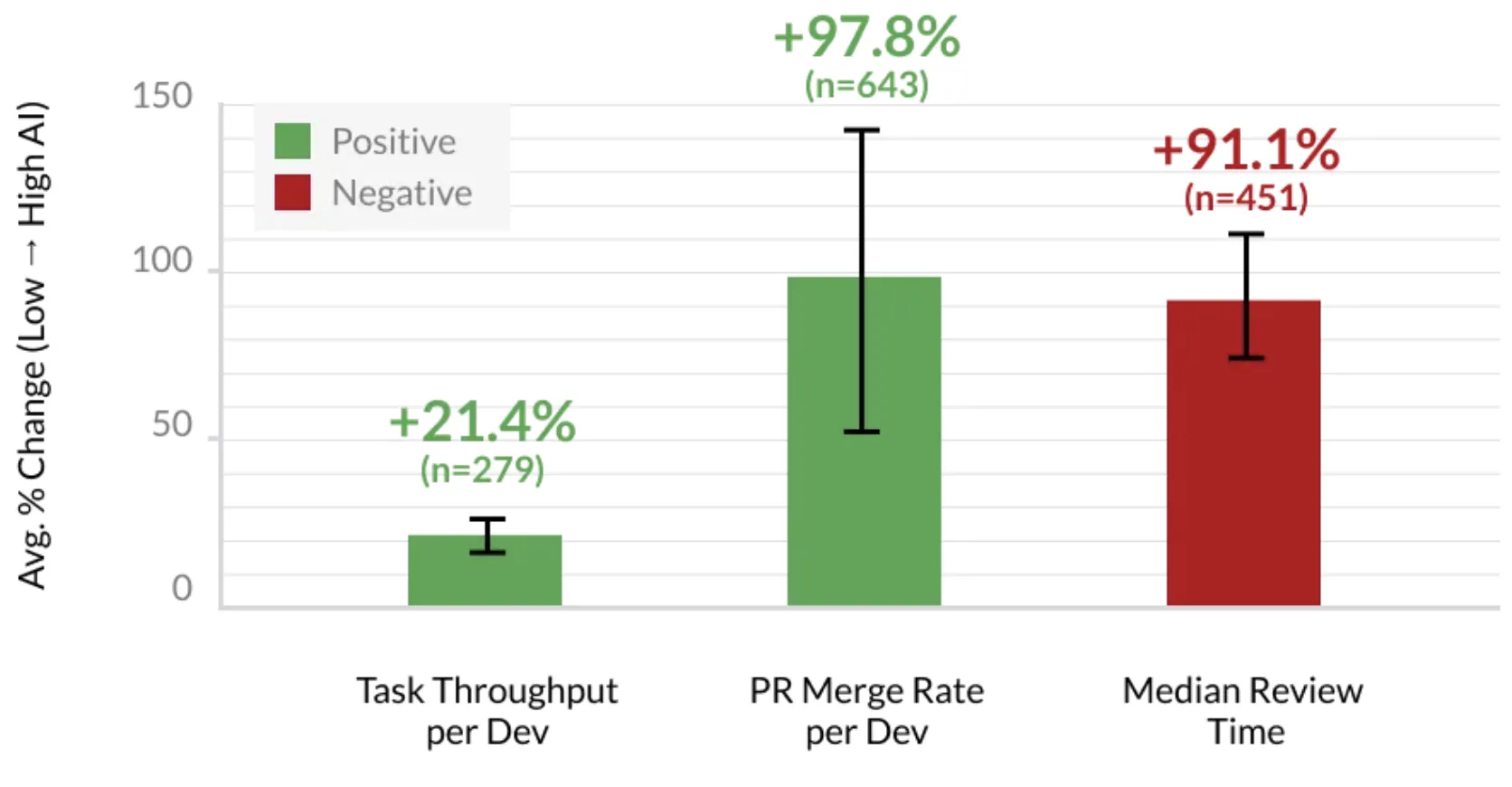
In other words: you may be moving faster locally while your organization pays for it in review queues and incidents.
Why “more review” is not a complete strategy
Teams typically reach for two levers. The first is AI-on-AI review: fast, scalable, and inconsistent. It can catch obvious issues; it will still miss classes of bugs that require grounded context about your system. The second is more human review: necessary, but expensive. When change volume doubles, review time does not scale linearly unless you staff for it.
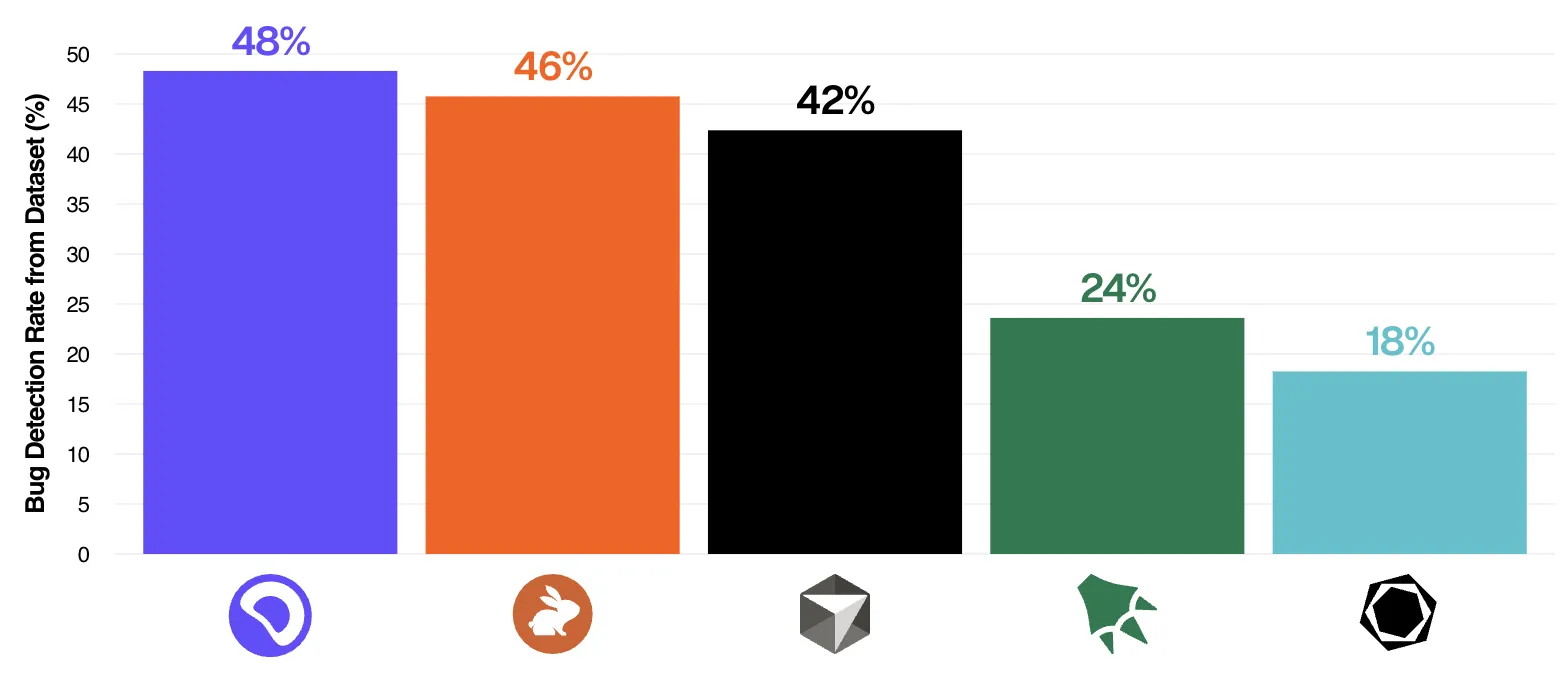
Even the best AI review tool catches roughly half of the defects in public benchmarks, according to independent evaluations of leading tools. That is a useful second opinion, not a substitute for proof. So the right question is not “human or bot?” It is what proof are we demanding before merge?
A testing pyramid for AI agents
Angie Jones, VP of Developer Experience at Agentic AI Foundation, published a testing pyramid for AI agents that reframes the classic unit/integration/UI model. In her version, the layers are not about test type. They are about how much uncertainty you are willing to tolerate at each level.
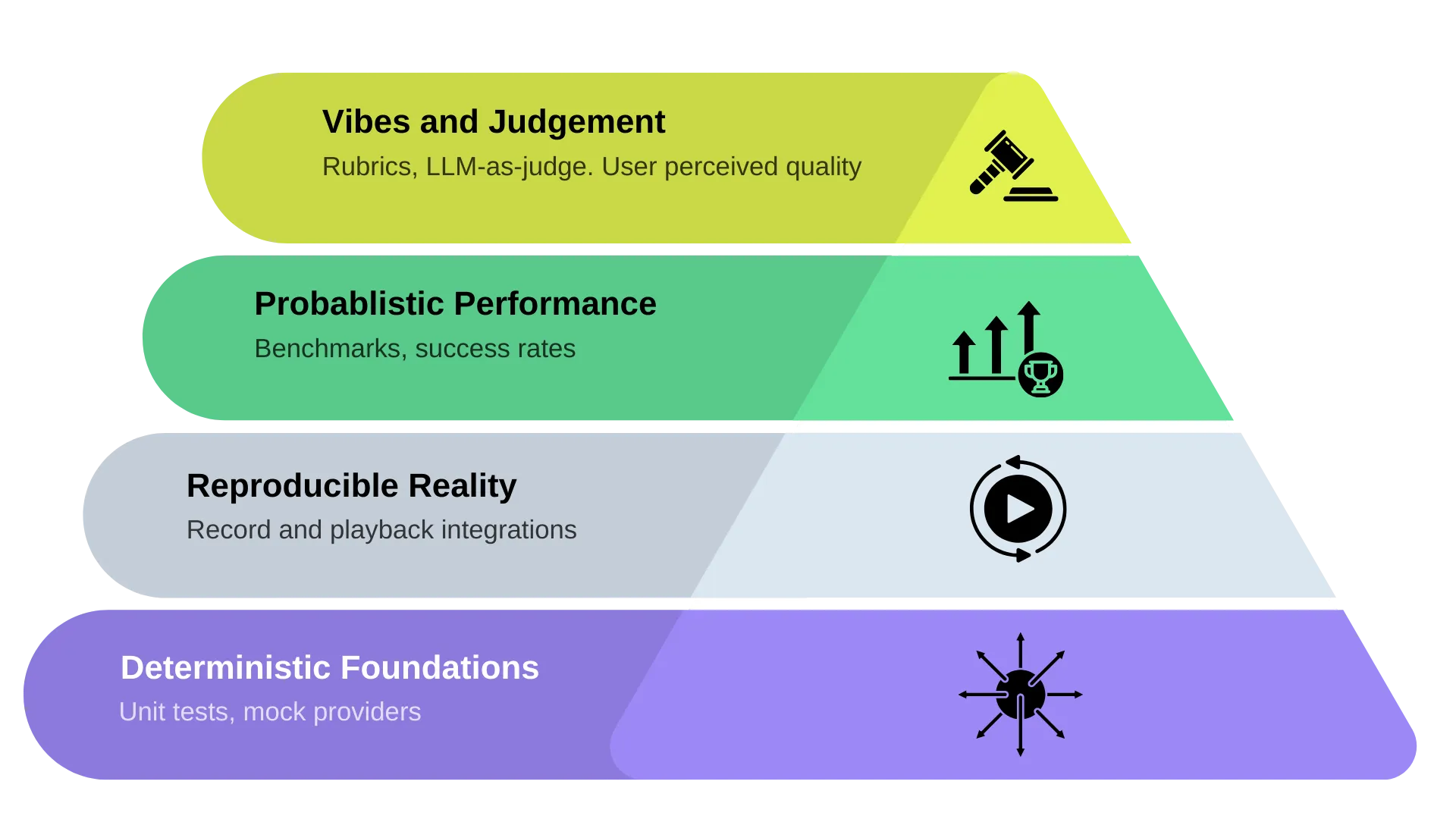
Image credit: Angie Jones, Block Engineering Blog.
Think of it from the bottom up.
1. Deterministic foundation (table stakes)
Unit tests, contract tests, and other repeatable checks that answer a simple question: did we break a behavior we already agreed was correct? This layer is boring on purpose. It is also the part many “AI-accelerated” workflows skip when speed is mistaken for progress.
2. Reproducibility
If an agent can reproduce a failure with the same inputs, same traffic shape, same sequence, it can often fix its own mistakes. If it cannot reproduce the issue, you get a familiar failure mode: tests pass, code “looks fine,” and the bug ships.
Reproducibility is where production context stops being optional. Abstract examples are not enough; your agents need signals grounded in how the system actually behaves: real API interactions, realistic payloads, and the messy edges that only show up under load.
3. Probabilistic judgment with good data
At scale, you will not get a perfect all-green matrix for every scenario. The goal shifts from “100% green forever” to risk-aware decisions: what changed, how likely is it to matter, and what did we learn from recent failures? That requires telemetry and baselines, not a single boolean gate.
4. AI-assisted review at the top
Using models to critique diffs can be useful as a layer on top of deterministic tests and reproducible scenarios, not as a substitute for them. “Vibe checks” belong here, not at the base of the pyramid.
Where most teams actually are
In practice, many organizations run a thin suite of tests, exercise a small fraction of the surface area, and lean on AI self-review to fill the gap. That is the inverted pyramid: fast feedback that feels smart, without the foundation that makes feedback meaningful.
Three layers that ground AI in real behavior
Speedscale is built to strengthen the bottom of the pyramid, deterministic checks and reproducibility, using traffic and behavior captured from real environments.
1. MCP and the agent loop
Plug into your AI coding agent (for example via MCP) so the model works with realistic API examples and scenarios, not only static snippets. When an agent can replay how code actually behaved against representative requests, it is far more likely to localize defects and propose fixes that survive contact with production.
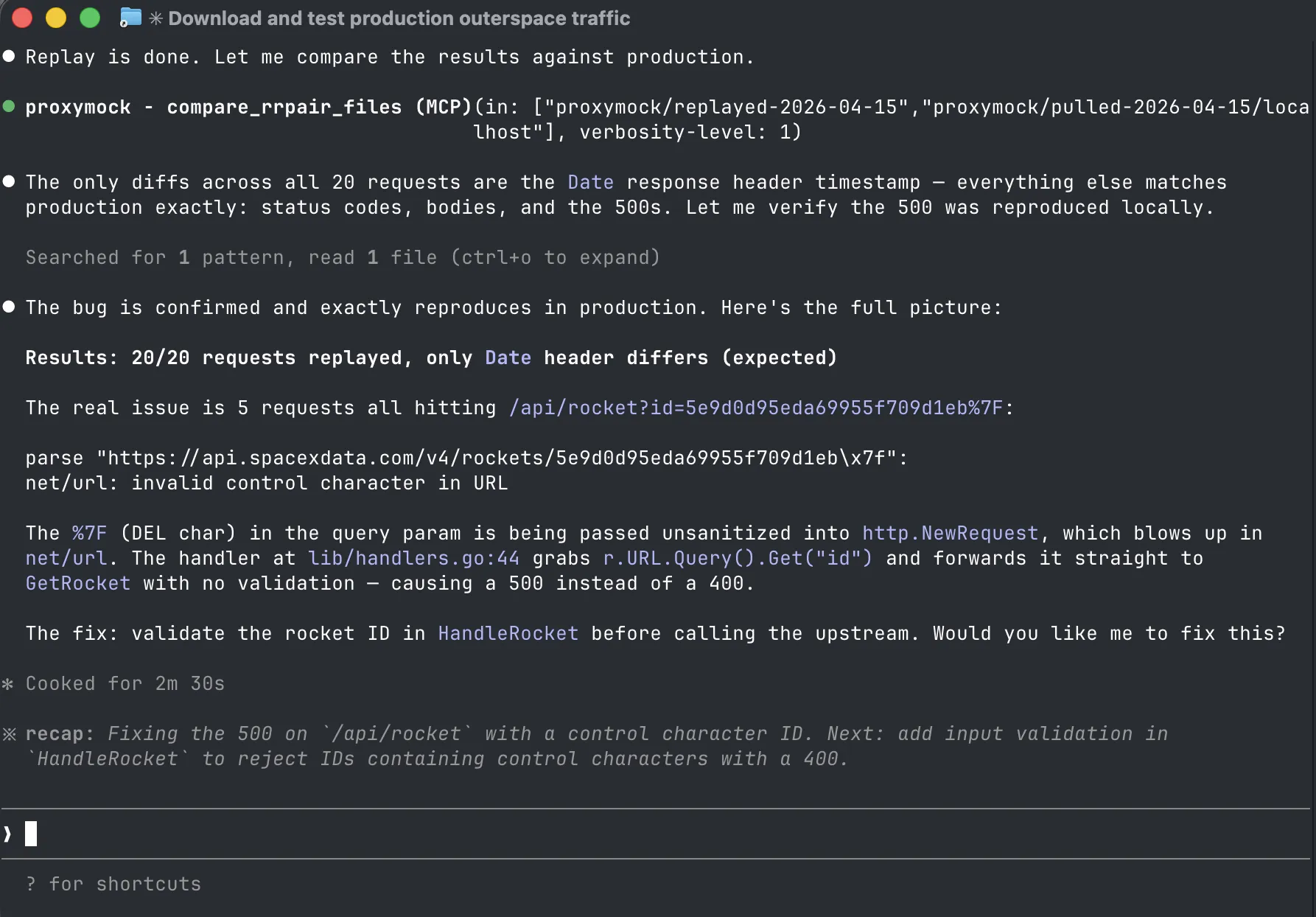
In the screenshot above, the agent pulls replayed traffic through MCP, compares it against production, identifies the five requests that reproduce the 500, reads the failing handler, and proposes the exact fix: input validation on the rocket ID. That only works when the agent has real request/response evidence to reason over.
2. CI that validates behavior, not just compilation
Your pipeline should do more than build and deploy. Run scenario-based checks against the same classes of data you trust for correctness. Snapshot traffic, replay it against branches, and treat differences as signal. Either block the merge or surface a clear report for human review. That turns CI into a regression baseline instead of a compile checkbox.
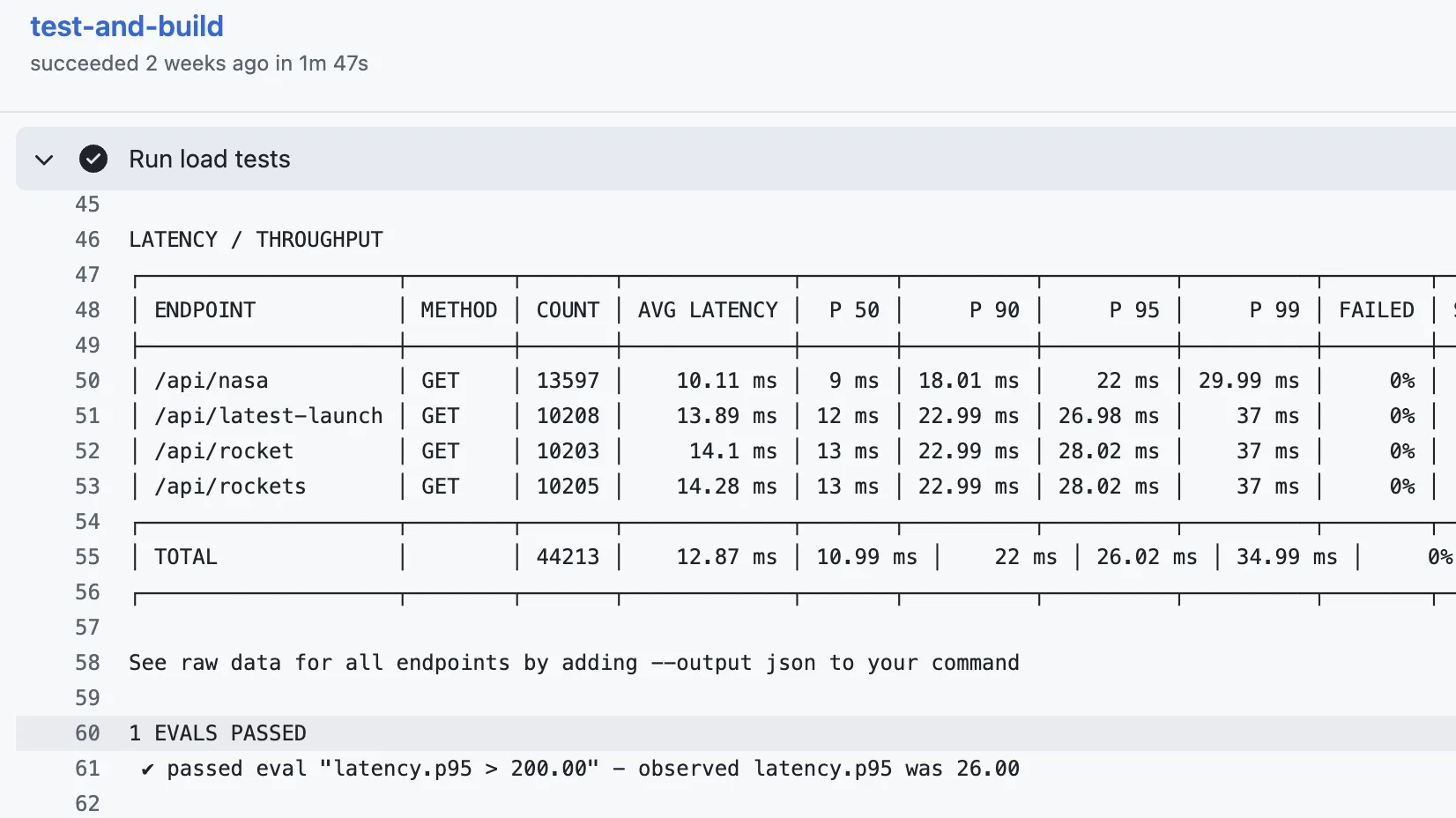
You can tune gates to your culture: fail the build on contract drift, or run as a copilot that asks, “This API shape changed, was that intentional?” Either way, you amplify human review instead of drowning it in raw diff volume.
3. Pre-production performance and resilience
Before you promote to production, exercise the change under realistic volume and error budgets. Did error rates move? Did tail latency spike? Did throughput collapse under a load profile that matches what you actually run?
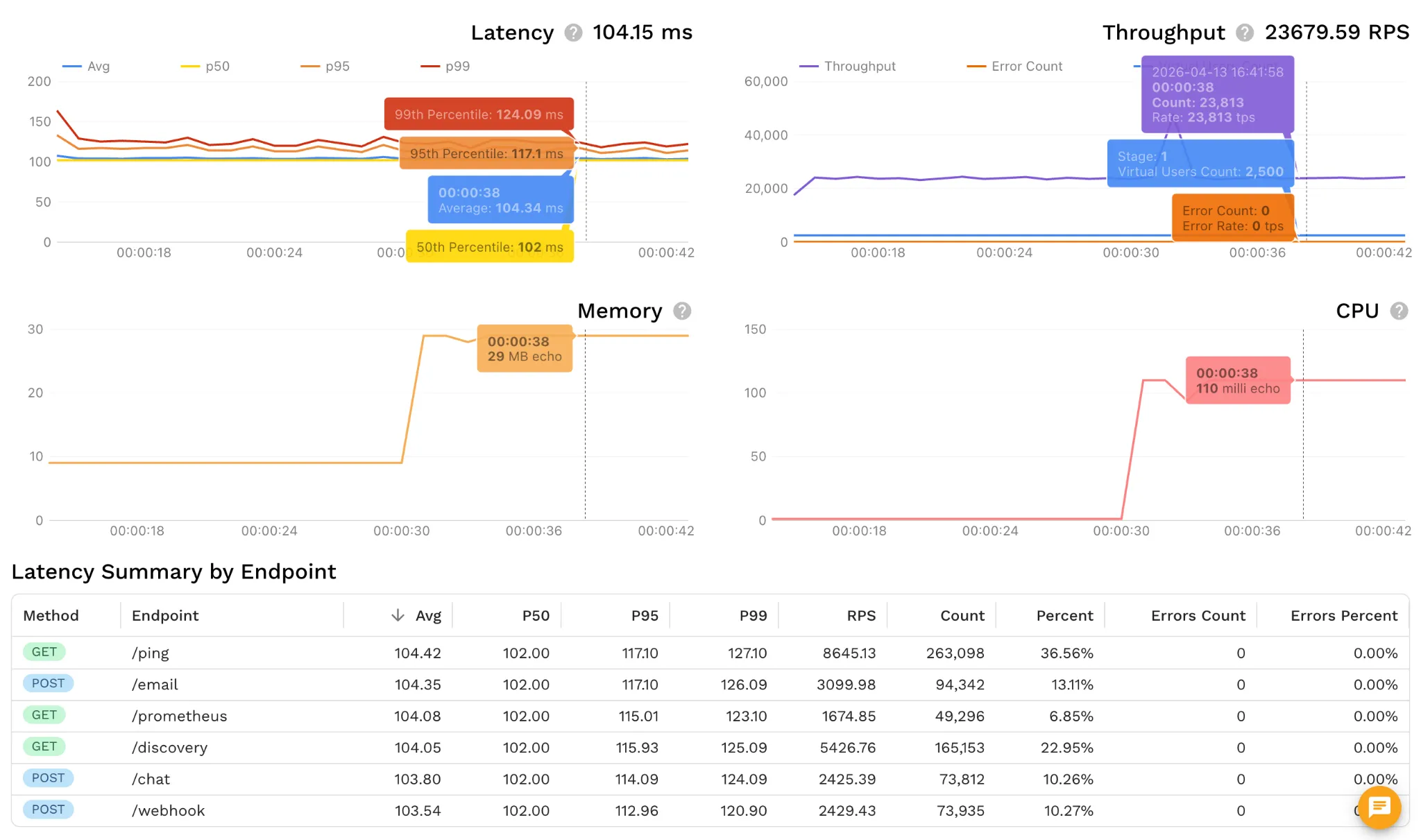
At Speedscale, we treat this as a standard quality gate. The dashboard above is from our own release process: a mock-server unit sustaining ~23,000+ RPS with p99 around 124 ms and zero errors. It is part of a reference architecture that flags regressions before they reach production.
Platform snapshot
On one side, open tooling like proxymock helps developers and agents work with proxied, replayable traffic locally. On the other, Speedscale Cloud integrates with environments where your systems already run, capturing traffic across protocols (including paths that are easy to miss in basic HTTP-only tests), supporting encryption, databases, and other real dependencies. When data sensitivity matters, you can redact fields or keep data inside your VPC next to production-adjacent workloads.
What customers use it for
Cimpress, Vistaprint’s parent company, has used production-derived traffic to shorten test cycles substantially, on the order of weeks to days in published accounts, while keeping regression and scale checks realistic ahead of peak seasons. IHG spins up large numbers of ephemeral environments to change core APIs such as reservations without guessing whether a refactor broke downstream behavior. Teams with strict data boundaries capture traffic in-region and keep it under their control (see data sovereignty and traffic replay) so engineering can reproduce issues without moving sensitive payloads into environments they do not govern.
What implementation looks like
You can still design on paper: application fit, technology fit, and a reference architecture that matches how your services talk to each other. From there, a focused rollout installs capture and replay paths in your environment, builds visibility into real traffic, and turns that visibility into tests and scenarios you can run repeatedly as AI accelerates change.
If you want to explore whether this fits your stack, start at speedscale.com: try the free tooling, book a conversation, or join the Slack community.
Further reading
- A developer’s guide to improving AI code reliability
- Silent failures: why AI code compiles but breaks in production
- Runtime validation vs. static analysis
- Angie Jones — Testing Pyramid for AI Agents
- Faros AI — The AI Engineering Report (Acceleration Whiplash)
- Stack Overflow 2025 Developer Survey — AI section