Testing in production simply means testing new code changes in production, with live traffic, in order to test the system’s reliability, resiliency, and stability. It helps teams solve bugs and other issues faster, as well as effectively analyze the performance of newly released changes. Its overall purpose is to expose problems that can’t be identified in non-production environments for reasons that may include not being able to mimic the concurrency, load, or user behavior. It’s a proactive way to prevent your system from a full-blown outage. Once a new piece of software is released to production, either in the form of a new feature or changes to the existing system, then you can perform tests in production using several different techniques, like:
- Canarying
- Feature Flagging
- Traffic Swapping
- Load Tests
- Shadowing
- Tap Compare
- Integration
- A/B Tests
- Logs/events monitoring
All of these require a significant amount of automation, without impacting the user experience.
The State of Testing in Production Today
Historically, a tester has been responsible for testing scenarios in non-production environments, prior to release. But in today’s world, developers are expected to test continually in order to provide constructive feedback and improve overall product delivery. Cloud environments offer the scale and ease needed for testing complex interfaces, something local setups can lack. When it comes to microservices architecture, numerous challenges require a well-defined testing strategy. Services communication, cyclic dependencies of each service, and distributed logging influence debugging, security, data consistency, performance tracing, and failovers of each service. While testing early in the pipeline shift-left testing is necessary, it’s still not enough. No tooling can replicate every user behavior in production. Using shift-right testing can help to uncover new and unexpected scenarios. Microservices testing can be cumbersome when you start diving into a different tech stack, dependency management, feature branches, protocols support, database schema, and migrations. And it’ll get exponentially harder with new changes. For effective integration testing, you need to have an in-depth understanding of services’ versioning, contracts, and communication protocols like REST and gRPC. The bugs collected from production help a team proactively improve system quality and provide a better customer experience. According to an oft-quoted but lost-to-time Netflix tech blog post from 2012, “The best defense against major unexpected failures is to fail often. By frequently causing failures, we force our services to be built in a way that is more resilient.”
The Limitations of Testing in Production
Perhaps obviously, testing in production should not be used by systems that hold users’ personally identifiable information (PII) in any form. Organizations in healthcare, finance, and government have to be particularly concerned with security and compliance. And no business in any industry can afford for production testing to impact application performance. If there’s no backup plan for your application, then severe risk for data loss is a given. In case of an outage with no planned rollback, you’ll end up exposing potential vulnerabilities and losing customers. Production tests should be an extension of your existing testing framework. If you bypass non-production environment testing, you’ll end up losing more than you gain from it. All the criteria you’ve defined for your testing should be covered before you try production tests. If not, be prepared for frequent outages, loss of data, code smells, and bad user experience. It may be tempting to adopt testing in production to promote a faster time to market, but production testing is a reactionary way to handle outages and issues; it’s used to tackle surprises. If you’re solving issues that could have been addressed beforehand in a testing environment, then you’re not exercising the true potential of production tests—you’re just hampering the system and draining your developers. Monitoring is, of course, indispensable at every phase of production release, but it can get expensive fast. For effective monitoring, you need to identify a core set of metrics consisting of the hard failure modes of a system, such as an increase in latency, an increase in the error rate, or a complete outage. Ensuring that code passes all necessary tests before being pushed into production will go a long way toward keeping your monitoring efficient and cost-effective.
How to De-risk Testing in Production
The best thing you can do to make testing in production less risky is to perfect your non-production environment tests. Consider Mike Cohn’s test pyramid. 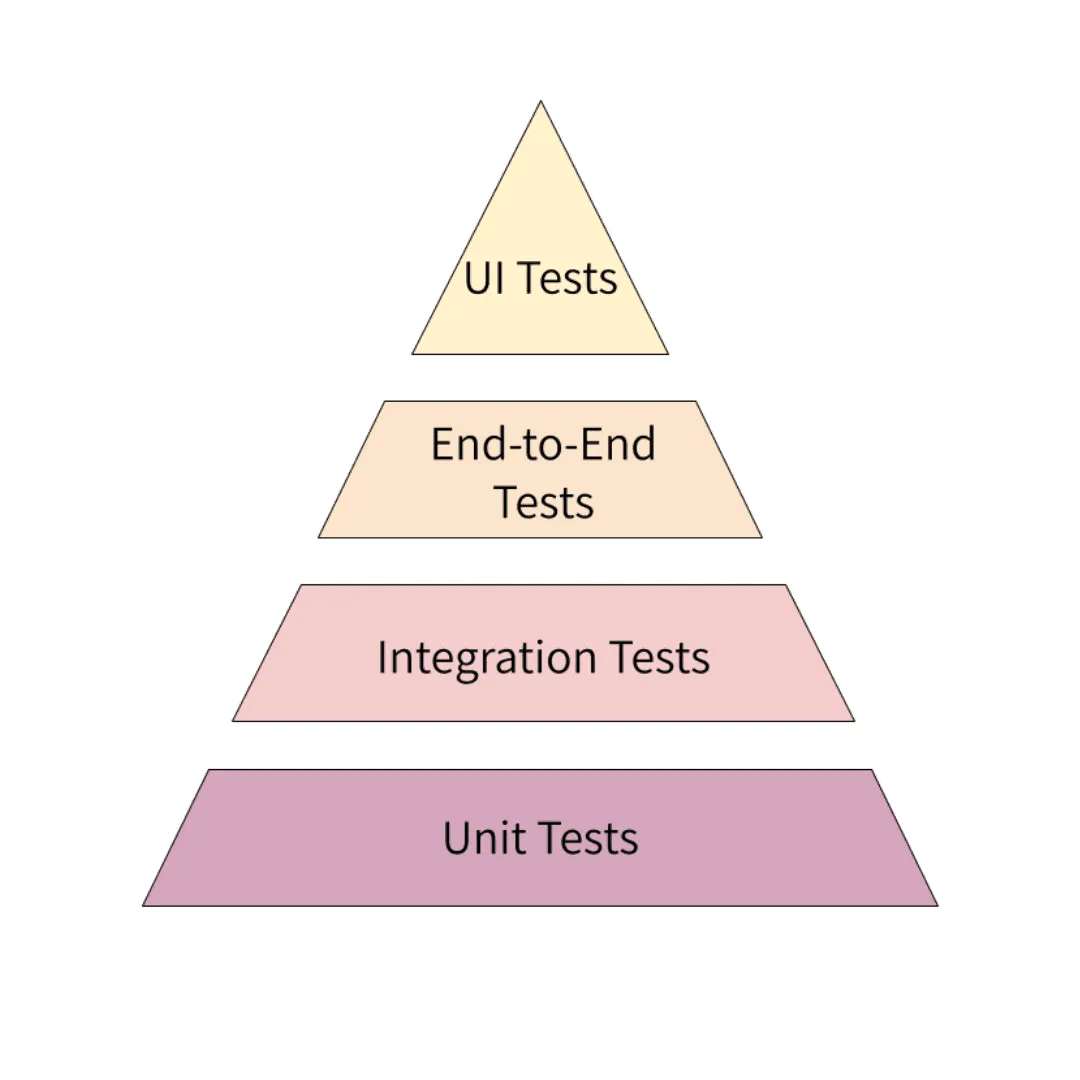 As you move toward the top of the pyramid, the scope of the tests increases and the number of tests to be written decreases. Unit testing is about validating each business logic in smaller units. By keeping the test suit small, focused, and high value, you can focus more on testing the behavior of the module by observing changes in their state and analyzing the interactions and collaborations between an object and its dependencies. In integration testing, the aim is to verify all the interactions between the components and check for any incorrect assumptions each microservice has about how to interact with its peers. Cindy Sridharan coined the Step Up Rule for how to best design integration tests. The idea is to test at one layer above what’s generally advocated for. With end-to-end testing, the intent is to verify that the system as a whole meets all the business goals, providing necessary coverage for any gaps between subsystems. Google’s blog post “Just Say No to More End-to-End Tests”says: “If two units do not integrate properly, why write an end-to-end test when you can write a much smaller, more focused integration test that will detect the same bug? While you do need to think larger, you only need to think a little larger to verify that units work together.…Google often suggests a 70/20/10 split: 70% unit tests, 20% integration tests, and 10% end-to-end tests. The exact mix will be different for each team, but in general, it should retain that pyramid shape.” Load testing sends simulated HTTP traffic to a server to measure performance, analyze server resources (CPU, memory, etc.), server response time, and server capacity, and find the parts of the system that are resource-intensive. Of course, if you’re going to be efficient with your testing, it’s important to invest in quality tooling. Consider checking out some popular testing tools and frameworks, such as:
As you move toward the top of the pyramid, the scope of the tests increases and the number of tests to be written decreases. Unit testing is about validating each business logic in smaller units. By keeping the test suit small, focused, and high value, you can focus more on testing the behavior of the module by observing changes in their state and analyzing the interactions and collaborations between an object and its dependencies. In integration testing, the aim is to verify all the interactions between the components and check for any incorrect assumptions each microservice has about how to interact with its peers. Cindy Sridharan coined the Step Up Rule for how to best design integration tests. The idea is to test at one layer above what’s generally advocated for. With end-to-end testing, the intent is to verify that the system as a whole meets all the business goals, providing necessary coverage for any gaps between subsystems. Google’s blog post “Just Say No to More End-to-End Tests”says: “If two units do not integrate properly, why write an end-to-end test when you can write a much smaller, more focused integration test that will detect the same bug? While you do need to think larger, you only need to think a little larger to verify that units work together.…Google often suggests a 70/20/10 split: 70% unit tests, 20% integration tests, and 10% end-to-end tests. The exact mix will be different for each team, but in general, it should retain that pyramid shape.” Load testing sends simulated HTTP traffic to a server to measure performance, analyze server resources (CPU, memory, etc.), server response time, and server capacity, and find the parts of the system that are resource-intensive. Of course, if you’re going to be efficient with your testing, it’s important to invest in quality tooling. Consider checking out some popular testing tools and frameworks, such as:
Conclusion
Production testing can be a key part of ensuring high quality in application performance, as long as you take steps to mitigate the risk of it. Make it as efficient as you can by ensuring your preproduction tests are doing as much heavy lifting as possible, and consider adding tooling specifically to aid your production testing. Speedscale helps you generate traffic scenarios and automate scalable testing so you maximize developer hours and slim down processes, all while preventing production incidents. Why not schedule a demo today?