Python Observability : A Complete Guide
Observability is a critical element of modern software development, unlocking awareness across complex and distributed systems with ease. This has allowed developers to monitor, understand, and debug their applications effectively, leveraging existing resources for more efficient lifecycle management and iteration.
In the context of Python, observability is an engine for boosting and maintaining the performance, reliability, and stability of the implementation.
In this guide, we’re going to look at the key aspects of building and deploying Python observability, the importance of this process, and the tools available to implement it.

What is Python Observability?
Python observability refers to the ability of a developer or provider to monitor and understand the flow and state of data within a Python application. This is often done through the analysis of traffic and data such as logs, metrics, traces, attributes of data, telemetry, and other states.
Whereas traditional monitoring typically focuses just on a set of predefined metrics, observability focuses on using these metrics and other data states to provide insights across the system as a whole, providing the next stage of awareness - true observable interactions across functions and data sets, referred to in shorthand has “observability”.
Implementing observability unlocks some significant benefits for teams:
- Teams gain a deeper understanding of their application’s behavior, the interactions between the runtime method collection, the relevant server clusters, the database or data storage methodologies, and more.
- Adoptees can more readily identify and resolve performance bottlenecks or errors, especially those that are high in complexity, by observing each stage of the interaction.
- Teams can improve overall system reliability and quality, not to mention user experience, guiding new development and ensuring that processes capture information for further iterative improvement.
Why Observability is Critical for Python Applications?
Python code is used in an incredibly diverse set of use cases and industries - it’s likely that, even if you didn’t know it, you interacted with Python at some point today.
Accordingly, this ubiquity across simple to complex use cases shows that Python is powerful but diverse - and it is this diversity that can make it hard to debug, hard to observe, and hard to manage.
Observability is critical, offering some huge benefits:
- Proactive Issue Detection - observability helps detect anomalies and issues before they impact users. Issues can often get lost in too many logs or reporting avenues, but truly effective observability can surface the most critical issues when they must be addressed.
- Efficient Debugging - with detailed insights into application behavior, developers can quickly pinpoint root causes. This can be especially helpful with multiple code changes or shifts in functionality, which can make finding the actual problem a bit difficult in many cases.
- Performance Optimization - observability data enables fine-tuning of application performance and resource utilization. Critical metrics in observability are often collected automatically removing the headache that data collection for performance can introduce for smaller teams.
- Scalability Management - as Python applications scale, observability ensures that performance and reliability are maintained. By setting instrumentation goals and limit trigger on your Python app, you can ensure that scaling happens efficiently while being aware of the cost of this scaling.
Core Pillars of Observability in Python
There are three core pillars of observability:
- Logs - Logs capture events that occur within an application, such as user interactions or data transfer. These logs are incredibly useful for tracking errors, creating tripwires for fail points, and creating trigger alerts for specific actions. Effective logging in Python requires a deep understanding of the traffic and patterns of utilization across an implementation.
- Metrics - Metrics are quantifiable data about an application’s performance, such as its response time, the rate of errors across interactions, triggered warnings, and so forth. Common instrumentation libraries like prometheus-client or statsd are used widely to track metrics.
- Traces - Traces show the end-to-end flow of a request or transaction through an application. This details the specific interactions of each component and the eventual service of that request. Distributed tracing tools like the OpenTelemetry Python SDK have allowed high integration for end-to-end visualization.
Tools for Python Observability
Python has several tools and frameworks for boosting and observability, with their specific value proposition being determined mainly by your observability goals and specific implementation within your system. Many companies will use one or many of the tools we discuss below, and many more exist within the market. These range from APM tools, like Datadog, to tools more focused on logs and tracing, such as ELK and OpenTelemetry.
Datadog
Datadog is a structured logging and comprehensive monitoring platform that supports Python applications. It provides features for log management, metrics collection, and distributed tracing. With seamless integration via the ddtrace library, Datadog simplifies monitoring for both small and large-scale Python applications.
Pros
- Comprehensive Platform - Datadog combines monitoring, logging, and APM in one tool with extensive integrations.
- User-Friendly - Datadog offers an intuitive dashboard and quite robust alerting systems, making management that much easier.
- Cloud-Native - This solution is designed for modern cloud and containerized environments, removing a lot of the hassle of more generalized tools.
Cons
- Cost - Datadog can be quite expensive, especially for large-scale deployments or extended log retention.
- High Overhead - Datadog agents can consume significant resources on monitored systems, especially with higher logging levels and introspection.
- Proprietary - Datadog is proprietary, which risks vendor lock-in that can limit flexibility and portability.
Elastic Stack (ELK)
Elastic Stack, comprised of Elasticsearch, Logstash, and Kibana, is a powerful open-source solution for observability. Python applications can send logs, metrics, and traces to Elasticsearch for indexing and visualization in Kibana, offering robust debugging and monitoring capabilities.
Pros
- Customizable - ELK is highly flexible and can be tailored to specific use cases.
- Open Source - since it’s freely available with high community support, adoption typically comes with reduced licensing costs.
- Scalable - ELK is pretty scalable, making it suitable for handling large volumes of data, particularly in log aggregation.
Cons
- Complex Setup - ELK requires significant time and expertise to configure and maintain.
- Resource-Intensive - while it’s powerful, this comes with high memory and CPU usage, especially in large-scale deployments. This can prevent its utility for smaller organizations that may not have resources for such a large setup.
- Fragmented Support - ELK is powerful and benefits from open source, but it also means that, unlike other enterprise solutions, you may have to rely on community forums or paid support if it’s not a perfect fit.
OpenTelemetry
OpenTelemetry is an open-source observability framework that supports Python applications. OpenTelemetry instrumentation enables developers to collect logs, metrics, and traces using a unified API and export data to various backends like Jaeger, Prometheus, or Grafana.
Pros
- Open Standard - OpenTelemetry is vendor-neutral and avoids lock-in by integrating with multiple backends.
- Interoperability - this solution works with various observability tools, including Datadog, ELK, and Prometheus, offering more complete coverage than other tools that don’t play well with others.
- Customizable - this solution is also highly flexible both in configuration and actual data collection, allowing flexible and tailored interactions with your infrastructure.
Cons
- Complexity - OpenTelemetry requires expertise to implement and configure effectively, introducing a substantial learning curve that can lead to poor configuration or implementation.
Limited Features - this solution is primarily focused on data collection, and as such, observability is a side effect as opposed to a core offering.
- Evolving Ecosystem: - this solution is still maturing, resulting in some gaps in documentation and tooling compared to established solutions.
Speedscale
With a different approach than the other solutions mentioned above, Speedscale can also be leveraged for observability and testing. Designed to capture, log, replay, and simulate traffic, enabling teams to identify bottlenecks and optimize application performance before deployment.
It allows for tracking across diverse query, metadata, worker process, and automatic instrumentation domains, unlocking significant high-level traffic awareness. This has tack-on effects and beneficial attributes for security, tracking, management, and more.
Some benefits of Speedscale include:
- Improved Performance Testing - SpeedScale allows you to replay real-world traffic patterns and loads, helping to identify performance bottlenecks or scalability issues before they occur in production. This enables testing for extreme conditions, such as spikes in traffic or unusual patterns, as well as typical flows for iterative and controlled development.
- Enhanced Reliability - With accurate traffic replay and simulation tooling, SpeedScale helps ensure that applications function as expected under varying conditions. This reduces the risk of system crashes or degraded performance during production.
- Faster Debugging and Development - By replicating production traffic in staging or development environments, developers can identify and resolve issues more quickly in a way that aligns with the actual production use case. This can save a huge amount of time, reducing the need for manual instrumentation, validation testing, creating mock traffic and backends, etc.
- Seamless CI/CD Integration - Speedscale integrates seamlessly with CI/CD pipelines, enabling automated performance testing as part of the deployment process. This can help ensure that new code doesn’t introduce any performance regression or degradation and that existing functionality is bolstered and protected.
- Cloud-Native Focus - Speedscale is designed for both traditional and modern cloud-centric development paradigms, supporting modern architectures such as Kubernetes, containers, and serverless environments.
- Cost-Effective - Speedscale is a very cost-effective solution. Beyond its free 30-day trial, it offers scalable cost models that mean orgs, both large and small, can make effective use of the systems at hand without having to worry about scaling into extreme cost.
Implementing Observability in a Python Application

Conclusion
Speedscale can help deliver unprecedented Python observability with very little effort, and for this reason, it has become a beloved tool by many developers! You can get started quickly and with little overhead, allowing teams large and small to get started with observability and replay almost immediately.
If you’re interested in using Speedscale, you can get started with a free trial - Speedscale offers a 30-day trial period for you to use all of the features in your own stack to really get a feel for the power and versatility of the platform.
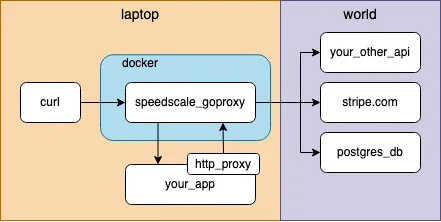
Speedscale can do all kinds of fancy things like transparently unwrapping TLS and tracking multiple traffic snapshots. You can find out more about it in the docs.
Get started with Speedscale
Visit the Quick Start for Speedscale
https://docs.speedscale.com/quick-start/
Alternatively, you can skip ahead and install using curl:
sh -c "$(curl -Lfs https://downloads.speedscale.com/speedctl/install)"