Run Local LLMs on Mac to Cut Claude Costs
TL;DR
- Use premium LLMs for high-level planning; route sub-tasks to local models where quality holds.
- Enforce deterministic evals (traffic replay, golden tasks) to guard quality.
- On a Mac,
qwen3.5:122bandqwen3-coder-nexthandle many coding chores well, like a junior engineer with guardrails. - Results depend heavily on your eval harness (e.g., Kubernetes traffic replay-style checks). Without it, local LLMs will not pay off.
- Claude remains superior for complex coding, but much of the “intelligence” actually lives in your harness, so you lose less than you think.
Why a Hybrid Approach
Part of the motivation for this post is how cloud API economics are shifting: Anthropic is moving large enterprise customers toward per-token, usage-based billing (unbundled from flat seat fees), which makes “always call the API” a moving cost line for teams at scale. A hybrid or local layer is one way to keep spend bounded while you still use premium models where they matter.
Cloud LLMs like Claude are excellent for high-level reasoning, planning, and tricky edge cases, but they get expensive fast. Local models (running via Ollama) are fast, private, and essentially free after setup. The winning pattern is to use cloud models for what they do best (global reasoning and plan synthesis), then execute as many leaf tasks as possible with local LLMs, monitored by strong, deterministic evals.
Benefits:
- Cost: Offload the bulk of tokens to local models.
- Latency: Local inference can be snappy and offline-friendly.
- Privacy: Keep sensitive code and data on-device.
- Control: Deterministic evals shape behavior and enable safe automation.
The Setup: OpenCode + Ollama + Qwen on Mac
We’ll use OpenCode to unify model access and routing, and Ollama to host local models. Here’s an example OpenCode provider configuration (the JSON $schema matches OpenCode’s config.json schema; see Ollama’s OpenAI-compatible API for the local baseURL) targeting a local Ollama endpoint with the specific models we’re using:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (local)",
"options": {
"baseURL": "http://127.0.0.1:11434/v1"
},
"models": {
"sorc/qwen3.5-claude-4.6-opus": {
"name": "sorc/qwen3.5-claude-4.6-opus",
"reasoning": true,
"tools": true
},
"qwen3-coder-next:latest": {
"name": "qwen3-coder-next:latest",
"reasoning": true,
"tools": true
},
"qwen3.5:122b": {
"name": "qwen3.5:122b",
"reasoning": true,
"tools": true
},
"qwen3-coder-next": {
"name": "qwen3-coder-next",
"reasoning": true,
"tools": true
}
}
}
}
}The npm field pulls in the Vercel AI SDK’s OpenAI-compatible adapter so clients can speak the OpenAI wire protocol to Ollama’s local /v1 endpoint.
With this, your orchestrator can call local Qwen variants via Ollama while still reaching out to premium APIs when needed. If you are validating agent output against real traffic, AI code verification is a useful framing for the same class of problem.
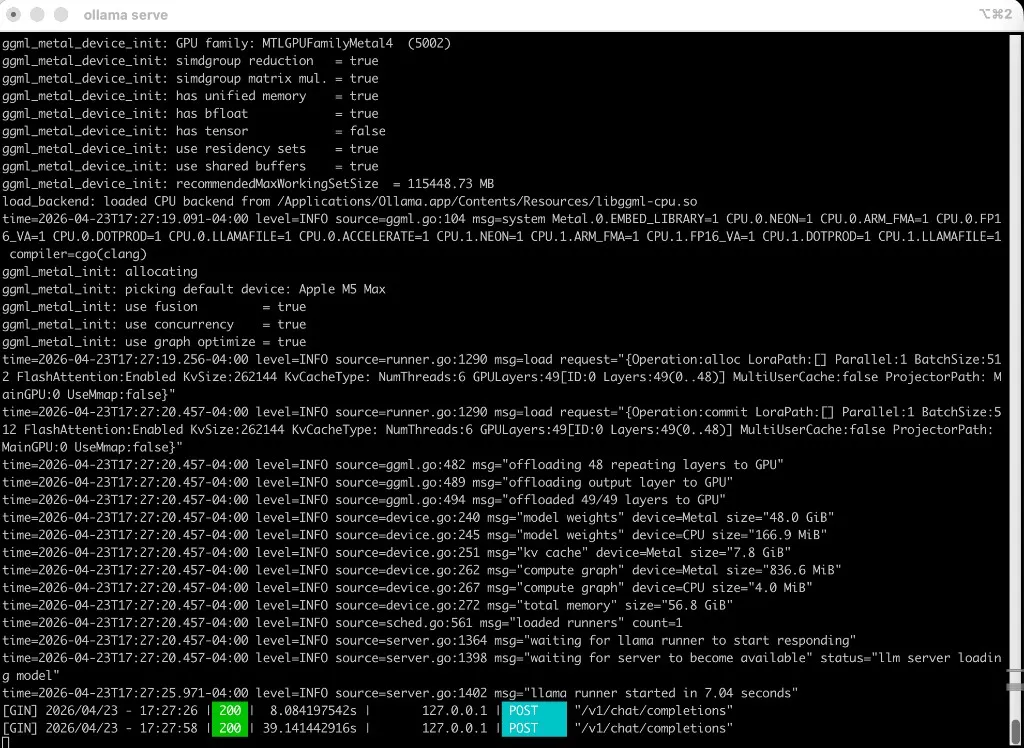
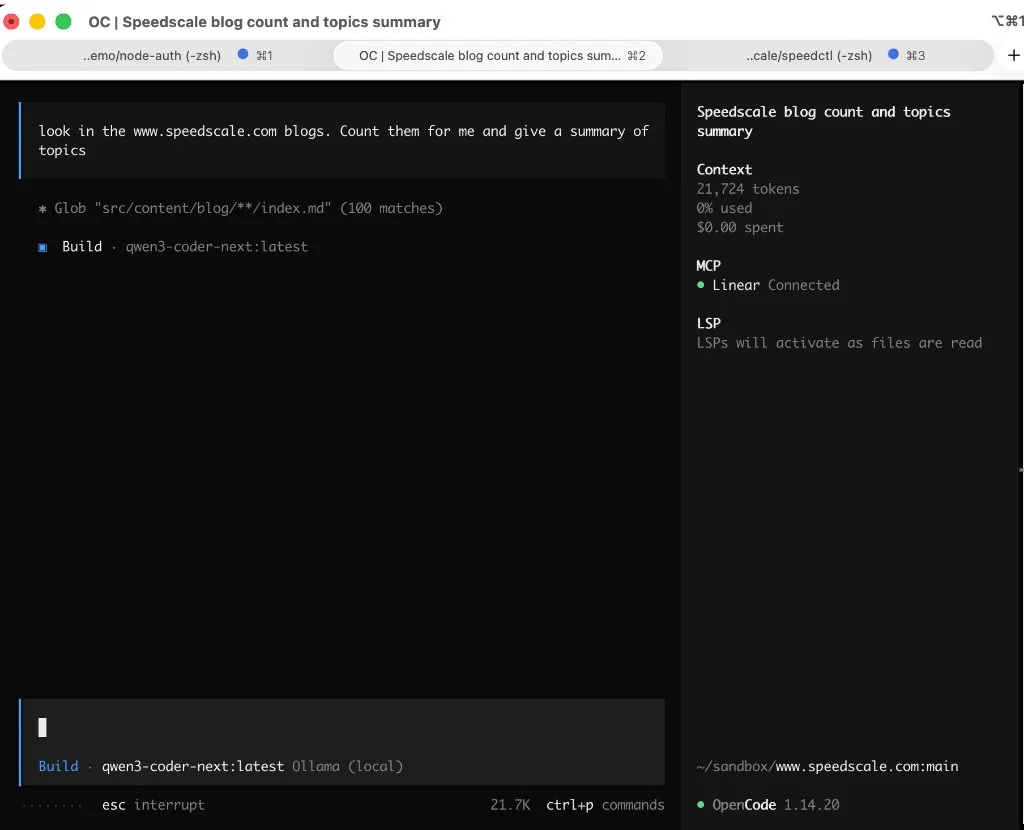
Here is a real run on an Apple M5 Max: Ollama serving in one terminal (ollama serve, Metal-backed model load, POST /v1/chat/completions returning 200), and OpenCode in the other, globbing the blog and summarizing on qwen3-coder-next:latest with $0.00 spend because everything stayed local.
Ollama: local server, Metal-backed model, successful POST /v1/chat/completions (200):
OpenCode: blog count / topic summary on qwen3-coder-next (Ollama local), $0.00 spend:
Orchestration Flow: Plan in Cloud, Execute Locally (When Safe)
-
Planning with premium LLMs (e.g., Claude):
- Feed a brief plus assets (repo map, constraints, acceptance tests) to generate a high-level plan and a set of subagent tasks.
- Ask the planner to annotate each task with estimated complexity, risk, and tool requirements.
-
Routing sub-tasks:
- Low/medium complexity coding tasks → local
qwen3.5:122borqwen3-coder-next. - High complexity, ambiguous, or safety-critical tasks → premium APIs.
- Long-context synthesis, intricate refactors, or novel domains → premium APIs.
- Low/medium complexity coding tasks → local
-
Guarded execution:
- Every sub-task runs behind deterministic evals (see next section) to accept or reject outputs automatically.
- Fail-close policy: if a local model fails evals, auto-escalate to the premium model.
-
Aggregation and review:
- Merge results, run the full test/eval suite, and cache successes for future replay.
Deterministic Evals: The Non-Negotiable Safety Net
Choosing which LLM “can do what” is still difficult. You can mitigate this by enforcing deterministic evals, mechanisms that do not trust the model but verify outcomes with repeatable checks:
- Traffic replay: Capture real traces (prompts + expected outputs + side effects) and replay them against candidate models. A Speedscale-style harness, grounded in Kubernetes traffic replay, shines here. For a related take on LLMs plus replay, see Unlocking AI coding reliability with traffic replay.
- Golden tasks: Curate canonical tasks per domain (e.g., code fix patterns, refactor templates, doc updates) with strict acceptance criteria.
- Programmatic assertions: Use unit/integration tests, linters, type-checkers, and schema validators as hard gates.
- Budget guards: If an attempt exceeds time/tokens or flaps between states, route up to premium.
Without this harness, local LLMs are hit-or-miss. With it, they’re surprisingly reliable for a large slice of routine work.
Local Qwen on Mac: What It’s Good At
On a Mac, Qwen family weights such as qwen3.5:122b and qwen3-coder-next do well on many coding chores:
- Boilerplate and scaffolding
- Straightforward bug fixes and refactors
- Test generation around existing patterns
- Code explanations, summarization, and doc hygiene
But treat them like a junior engineer:
- Provide precise task briefs and constraints.
- Enforce eval gates (tests, linters, compile checks) before merge.
- Keep changes small and observable; avoid broad, speculative edits.
- Use tool/function calling with a narrow, well-audited toolset.
In practice, this covers a surprising percentage of day-to-day dev tasks. When they hit ambiguity or crosscutting concerns, escalate.
128GB-class models, one user on a Mac
The largest Qwen weights we discuss here (for example qwen3.5:122b) are in ~128GB of memory in common local setups. That is workable on a Mac with enough unified memory if you treat the box as a single-user workstation: one person or one primary inference session, not a shared service for a team.
If you need several people or several concurrent inference workloads on one machine, a Mac is the wrong place to centralize. Prefer something built for that, such as NVIDIA DGX Spark: it uses a Blackwell-class stack (Grace Blackwell / GB10) and is aimed at running more than one heavy inference path at a time with headroom, compared to stretching a single-user laptop or desktop.
Harness Quality Drives Outcomes
Different teams report very different experiences with local models. The model is only part of the story. The harness has equal impact:
- Coverage: Good goldens exercise real-world edges, not just happy paths.
- Automation: CI-enforced evals prevent regressions and allow safe batching of local tasks.
- Replay fidelity: High-quality traffic capture and consistent replay (see MCP, traffic, and the replay loop) make comparisons and regressions believable, not wishful.
If you do not have this, local LLMs will not consistently replace premium tokens. If you do, they often can, sometimes dramatically.
Routing Rules That Work Well
Here’s a simple starting policy you can refine as your eval coverage grows:
- Local by default if: task is CRUD-like, refactorable by tests, or idempotently checkable (linters, formatters, schema checks).
- Premium if: multi-file architectural changes, low test coverage, novel libraries, or strict compliance/security review.
- Always evaluate: route outcome through tests + replays; auto-escalate on failure or uncertainty.
- Cache and learn: label each task with which model passed evals; use history to improve routing.
Measuring Success
Track these to know it’s working:
- Token spend reduction (absolute and %)
- Success rate on local-first attempts
- Mean time to green (from plan → passing evals)
- Escalation rate to premium models
- Flakiness (variance between replays)
Limits and When to Escalate
Claude is still superior for complex coding tasks, deep planning, and novel problem solving. That said, much of the system’s intelligence lives in your harness: task decomposition, replay, and eval gates. With a solid harness, shifting a large portion of routine work to local models is realistic without large quality losses — in our experience, 40–80% is achievable once your eval coverage is solid.
Quick Start Checklist
- Install Ollama.
- Download the weights for every model you plan to call. One way is to run a model once so Ollama fetches it—for example,
ollama run qwen3-coder-next(the first run downloads; you can exit the session when the prompt appears). Repeat for each model in your OpenCode or CLI setup (qwen3.5:122b,qwen3-coder-next:latest, and any other tags you use) so they are all present locally. - Start the Ollama server in a second terminal with
ollama serve, and leave that window open while you work. On later sessions, run the same command in another window whenever you need the API and the server is not already running. - Set up OpenCode with the configuration above, with
baseURLset tohttp://127.0.0.1:11434/v1per Ollama’s OpenAI-compatible API docs. - Stand up your eval harness: tests, linters, schema validators, and replay or mock tooling. For a desktop-friendly way to work with recorded traffic, see proxymock.
- Start with local-by-default routing for safe tasks; measure and iterate.
- Add auto-escalation on failure and cache pass/fail metadata.
Appendix: Model Inventory (local via Ollama)
sorc/qwen3.5-claude-4.6-opus(tools + reasoning) — community fine-tune on Ollama Hub, not an Anthropic modelqwen3-coder-next:latest(tools + reasoning)qwen3.5:122b(tools + reasoning)qwen3-coder-next(tools + reasoning)
These cover most local coding flows; use premium APIs when tasks exceed your eval safety envelope.
If you want to try this workflow today, proxymock is a good starting point for building the replay harness that makes local routing trustworthy. Run it locally, capture real traffic, and use replays as your first eval gate.
Thanks
Thank you to Hugh Brien and JT for their contributions to this post. Any errors or rough edges are mine to fix.