As a team, we have spent many years troubleshooting performance problems in production systems. Applications have become so complex that you need a standard methodology to understand performance. Our approach to this problem is called the Golden Signals. By measuring these signals and paying very close attention to these four key metrics, providers can simplify even the most complex systems into an understandable corpus of services and systems. Today, we’re going to look at these Golden Signals of monitoring, defining what they are, how they function, and what insights can be gleaned from their identification and monitoring.
What are the Golden Signals?
There are many different variables that can be tracked to understand system performance and system health. Fortunately, right now, there are a couple of common frameworks we can borrow from:
- Google SRE Handbook on Monitoring Distributed Systems with the Four Golden Signals: latency, traffic, errors, saturation
- The USE Method popularized by Brendan Gregg: utilization, saturation, and errors
- The RED Method coined by Tom Wilkie of Grafana: rate, error,s and duration
Despite using different acronyms and terms, they fortunately are all different ways of describing the same thing.
Latency
The latency of a system is its response time. In essence, by measuring the duration or length of time it takes for a transaction to complete and HTTP requests to be resolved, you can measure both the user experience, the request flow, and the overall health of the service serving that request. In a user-facing system, high latency can impact user satisfaction quite significantly, leading to poor revenue and sentiment performance even when successful requests and high system reliability are assured. Monitoring latency must also take into consideration the resource utilization that comes into play. When a request is highly latent and highly expensive, you have a glaring red flag. Monitoring traffic and monitoring data to detect these issues can go a long way towards informing you as to where these performance issues might arise.
Traffic
Traffic is best designed as the throughput of data in a system. Also called the utilization or rate of usage, this metric reflects the number of transactions that are happening over a unit of time - for instance, the transactions per second or minute. This can reflect the overall efficacy of the network and its relevant network devices clusters, but can also help significantly in capacity planning, web service design for load balancing, and identification of performance bottlenecks in transit.
Errors
Error rates are the prevalence of significant errors across the system. This is often calculated as a rate or percentage of errors rather than just a core percentage, as this can help identify critical aspects concerning resource usage, service reliability, and overall performance degradation. When used as a data source in its own right for further processing, error data can be used to identify systemic issues via infrastructure monitoring tools, perform root cause analysis across various systems and web server stacks, and allow for a full audit of the software system. You should make sure you are collecting as much information around these errors as possible. just knowing that an error in your IT systems occurred is less than useful - having an HTTP status code or other red flag in your monitoring systems can help your software engineering and reliability teams make rapid fixes at scale.
Saturation
Saturation is a category of data that includes the overall utilization of resources across memory, processing data, I/O utilization, queue depth, and more. In essence, saturation can best be thought of as how much your system is being used and how effectively it is used. Think of saturation like a towel - a towel can only dry so much, and so the utilization of it is a good measure to see how much it can dry, how much moisture it’s already wicked away, and how much headroom is left in its ability to perform its duty.
Why Golden Signals Matter?
The Golden Signals are an incredibly powerful set of metrics that unlock a variety of insights into system health and potential tool integrations. The Golden Signals concept is based around providing as much information as possible around system stability, user demand, resource allocation, and other fundamental metrics - by tracking these Golden Signals, you can get a top down view of the overall health of your system, its components, and the network that it operates on. Visibility - and more pointedly, observability - is a critical aspect of effective service provision and utilization. Without seeing what’s going on with your system, you might as well be flying completely in the dark. Services at this scale are a bit like an ocean liner - would you rather be a captain with a full set of tools and tracking at your disposal, or would you rather go it alone without any systems telling you your course, risks, and obstacles?
What Should You Do with the Golden Signals?
The Golden Signals provide some incredible benefits and use cases. Let’s take a look at a few of them.
Better Insights
When looking at the Golden Signals, it’s helpful to consider the difference between data and information. Broadly speaking, data is not super useful - simple numbers just provide raw facts, but they don’t give you an insight into what that data actually means. Data becomes useful when it’s converted into information. While this is often accomplished through the use of visualization tools, you can’t just collect data and hope that it magically surfaces some insight. One thing you can do, however, is generate data that gives context to other points of data. This can give much better insights and a more comprehensive view of the overall service. For instance, it may not be helpful to know that you have a ton of reported errors. This tells you a problem has happened but very little else. When you bring together well-defined data in a structured way, you can more easily create information. In the context of the Golden Signals, this means a better view of what optimal performance looks like, a measure of your service level objectives, real insights into user traffic, and much more.
Advanced Tooling
This data doesn’t just provide context - it unlocks more functionality. Alerting mechanisms can be triggered based upon data thresholds, distributed application performance management can be enabled, systems monitoring saturation can be built with escalation pathways, and much more. The Golden Signals provided a way to engage in data collection that has a purpose, and because of this form and function, you can built these data pulses into other tools to track errors, reduce failed requests, and deploy effective monitoring. This can have huge impacts on positive user experience and overall system performance, allowing to do more complex and directed efforts across your product set. These toolsets include:
- Synthetic monitoring tools that allow for tracking key performance indicators across both simulated and real traffic;
- Reduction in alert fatigue by reporting only on the data that is necessary for continued IT operations;
- More advanced monitoring agents, such as those based in heuristics detection;
- Site reliability engineering suites that allow you to take more proactive measures for infrastructural and systemic reliability and much more.
Getting Started with the Golden Signals
The Golden Signals originate with Google’s work in Site Reliability Engineering (SRE), and as such, should be viewed within that context - site reliability, and specifically monitoring and maintaining reliable and flexible systems. These signals provide a structured framework by which the system’s health can be measured, and as such, should be used both as a general feedback provision as well as inputs for other tools. Accordingly, it’s essential to make sure that your systems have adequate and accurate measuring systems in place to ensure the accuracy of these metrics in real-time. Once you have made sure that you have adequate tooling in place, you can start integrating this data into systems through the use of integration pathways, as well as manual solutions such as thresholds and alerting to note when anomalies crop up (more on this in a minute). The ultimate goal of this process should be to use the Golden Signals in a dashboard-like toolset that gives you ultimate visibility, so you should be thinking of this approach both as a resultant output and a determinant input.
How to Detect Anomalies in Your System
Detecting anomalies in your system leverages the Golden Signals as a foundational metric, testing actual system performance against a preferred baseline. There are quite a few techniques that can be deployed to make this process more effective.
Define the Baseline
To detect deviation, you need to know where you’re actually coming from first. Using the Golden Signals, you can take a general measurement of what your system looks like both during regular and peak use. This will help you establish a baseline which you can test against over time.
Leverage Automated Systems for Alerting
From here, you can use automated alerts to detect anomalies across the system. This can help you track services, especially in complex environments, without the need for messy manual testing and observation.
Lean on Algorithms
Don’t be afraid to leverage algorithms for this process. Detection can be a fuzzy thing, and trying to figure out if something is truly abnormal or if it’s just a spike for something external, such as your service being shared on social media or covered in the news. Use techniques like machine learning, neutral networks, regression analysis, and other systems to more intelligently track your performance across the network.
Correlate Metrics and Signals
Anomaly detection is just one aspect of the Golden Signals benefits. Use this data to correlate your metrics and your signals for more effective tracking. For instance, increases in latency might correlate with higher traffic, but it might also correlate with increased use of a specific function; the former is hard to consider an anomaly as much as poor scaling, whereas the latter points to a bug within the function itself. Don’t just consider an anomaly something that must be resolved - drill down to the root cause and correlate systems to get a firmer understanding of your overall systems.
Tools to Monitor the Golden Signals
When choosing tools to monitor the Golden Signals, you need to really consider how these signals are surfaced and in what context. Simply surfacing this data isn’t very useful - it must be surfaced in a way that gives the data context and actionable insights. Accordingly, the best tools to monitor these signals are the ones that provide ways to interact and contextualize the data. Tools like Prometheus, Datadog, and Pingdom provide some basic level of observability, but work best in concert with other tools rather than singular solutions. The real benefit of the Golden Signals in immediate feedback and tracking at scale - and getting this right requires a bit more of an advanced solution.
The Speedscale Reports Dashboard
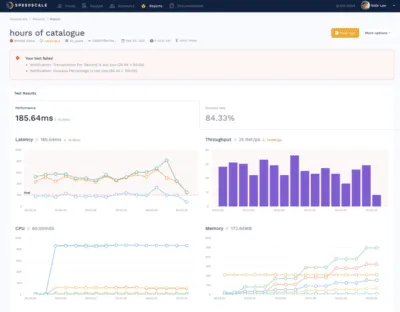
We have taken this data to heart at Speedscale. When we updated the design of our new Dashboard UI, the first thing we wanted to overhaul was the Report page. How do you know your app will perform quickly, efficiently, correctly, and at scale? This Speedscale Report gives you immediate feedback unlike anything else and allows you to make better release decisions. Here are some of the key aspects of this report:
- Your goals are summarized relative to the actual measurements. In the example above, this replay failed in terms of throughput and success rate.
- You can see each of the Golden Signal values on the screen. There is no need to click around and pull data from various sources.
- These Golden Signals are always available before you release so you can decide whether or not the code is ready for production.
From Monitoring to Testing: Using Golden Signals Pre-Release
Most teams only use golden signals reactively — watching dashboards after deployment. But what if you could validate golden signals before releasing? By replaying production traffic in a test environment, you can measure latency, throughput, error rate, and saturation against real-world patterns before code reaches production. This closes the gap between observability and testing.
Related reading:
- How to Determine Throughput with Performance Testing — measuring TPS as a golden signal
- Don’t Just Monitor SLAs — Validate Them Automatically — turning golden signals into automated pass/fail criteria
- Shift Left on Performance Testing — catching performance issues before production
- The Definitive Guide to Traffic Replay — using real traffic to validate golden signals pre-release
FAQ
What are the 4 golden signals of monitoring?
The 4 golden signals are latency (how long requests take), traffic (how much demand your system handles), errors (the rate of failed requests), and saturation (how full your system’s resources are). They were defined by Google’s SRE team as the minimum metrics needed to understand system health.
What is the difference between golden signals and the USE method?
Golden signals (latency, traffic, errors, saturation) focus on user-facing service health. The USE method (utilization, saturation, errors) focuses on infrastructure resource health. Golden signals tell you “is the user experience good?” while USE tells you “are the servers healthy?” Most teams use both.
How do you use golden signals for testing, not just monitoring?
Capture production traffic and replay it against a pre-release build. Measure the golden signals during replay and compare them to your production baselines. If latency spikes, throughput drops, or error rates increase, you’ve caught a regression before it reaches users. Tools like Speedscale automate this workflow.
Which tools are best for monitoring golden signals?
Prometheus and Grafana are the most common open-source stack. Datadog, New Relic, and Dynatrace are popular commercial options. For pre-release golden signal validation, Speedscale measures all four signals during traffic replay and compares them against production baselines automatically.