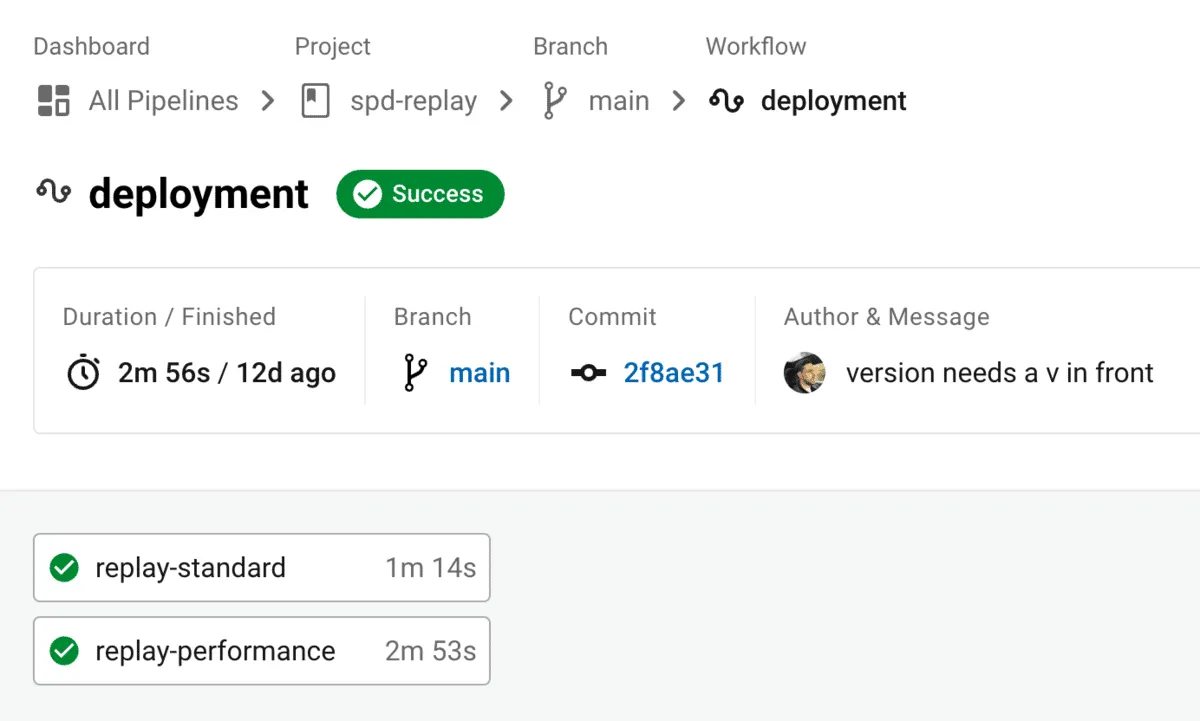
With over 50,000 active organizations and 250 million workflows, CircleCI is one of the most popular networked CI platforms. When getting started with CI pipelines, teams typically want to ensure that code will compile, pass unit tests, and build a container image. After catching these low hanging fruit of syntax errors, engineering teams need to dig much further to find business logic and scalability errors. By combining Speedscale with CircleCI, it’s now easier than ever to run container-level performance testing on every workflow.
Challenge #1 - Writing Load Test
One of the reasons why teams don’t run performance tests more frequently is that it takes a long time to write all of the test automation. Even though there are tons of free and open source options, the time investment to build test scripts adds up. It’s usually not obvious to understand what are the most commonly executed endpoints, and what data can be used in each call. With Speedscale, this data is automatically captured and visible in the Traffic Viewer. All of this data is automatically converted into test cases instantly with no scripting required.
![]()
Challenge #2 - Ramping Up the Load
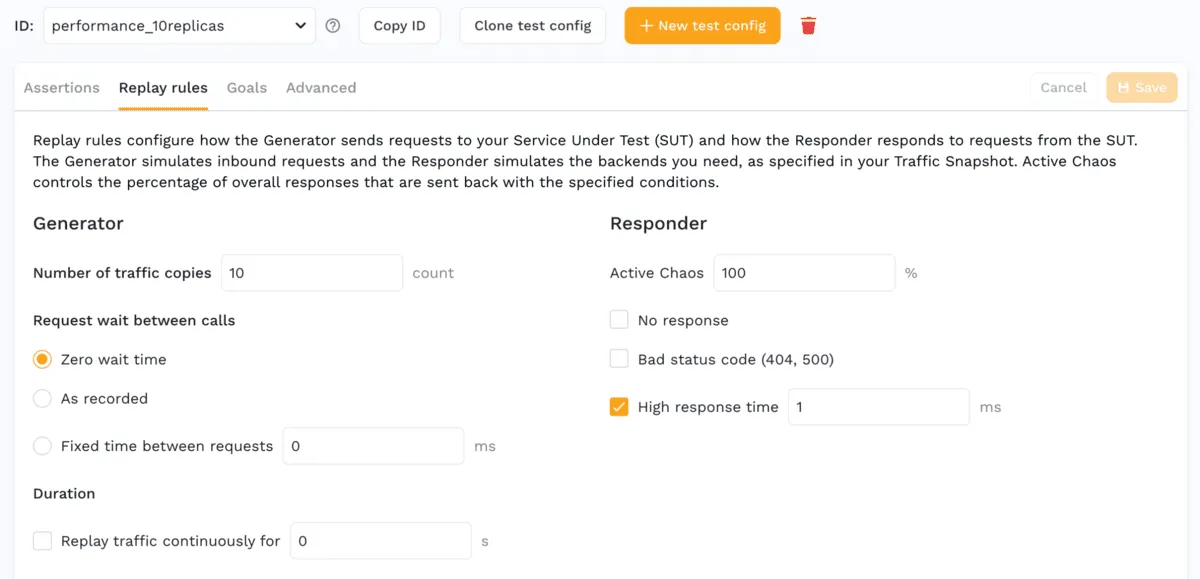
Even if you already have some integration tests with a desktop tool or unit test, you need some way to scale out the users even further. With Speedscale, this capability is called a Test Config and is a built-in requirement when you want to replay your traffic. Just select your favorite load configuration to scale up to a certain number of users or a specific amount of time. The exact same test can be run for load and performance, chaos engineering, or even functional validation.
Challenge #3 - Stable Environment for CI
Now that you have your load test, configuration and your app container, you’ll need an environment to run it in. Fortunately CircleCI has great support for containers, so you can run the container and push the load right in. However, most applications make calls to other services, and if those are not also provisioned with proper test data, you can get test case failures and false negatives. Speedscale solves this with Service Mocks which can automatically provide the correct responses your application needs, again with no coding or scripting required.
![]()
To configure Speedscale to utilize Service Mocks as part of your load test, all you have to do is set the mode to full-replay which will automatically configure network rules to send calls to mocked out endpoints in your cluster.
Compatibility with CircleCI
CircleCI utilizes the ORB technology to integrate with dozens of different services and platforms. Because Speedscale is fully compatible with Kubernetes, it’s possible to utilize this integration with their existing out-of-the-box Kubernetes ORB. At the top of your workflow, add the ORB for Kubernetes as well as one for your cloud provider (if required):
version: 2.1 orbs: aws-eks: circleci/aws-eks@2.1.2 kubernetes: circleci/kubernetes@1.3
In our example we are using AWS EKS, so running the load test is as simple as authenticating with the cluster and running a single script with some kubectl commands. The parameters of the deploy-replays.sh script references a directory where your manifests are stored:
steps:
- checkout
- kubernetes/install-kubectl: kubectl-version: << parameters.kubectl-version >>
- aws-eks/update-kubeconfig-with-authenticator: cluster-name: << parameters.cluster-name >>
- run: command: | tools/deploy-replays.sh performance
If you look inside the performance directory you can see a patch yaml that should look very familiar if you’re been using Speedscale. You just supply the values from the previous 3 sections of this blog:
- Snapshot of the traffic you want to replay
- Test config with the load rules
- Mode if you want to use
full-replayor justgenerator-onlyif you already have the right environment
apiVersion: apps/v1
kind: Deployment
metadata:
name: <
Full example code can be found here: https://github.com/kenahrens/spd-replay
Summary
In their 2022 State of Software Delivery Report, the CircleCI team highlights 4 key drivers to success with Continuous Integration. By utilizing Speedscale as part of your workflow you can improve in all 4 of these areas:
- Duration - pipelines that use Service Mocks will run faster than full-blown end-to-end environments that take much longer to set up and keep the data maintained.
- Throughput - teams with Speedscale guardrails will push code more regularly knowing that a robust set of tests simulating production conditions will be run each time, and know whether the code is safe to reach production.
- Mean Time to Recovery - when teams push smaller amounts more frequently, it’s easier to know which change caused a regression (if you have traffic replay tests like Speedscale offers).
- Success Rate - you can even run Speedscale locally on your desktop to catch issues before pushing the code or opening that MR. That way you get easy sanity tests to find issues even before code check-in.
If you have more questions about this integration or others, please find us online on our Community Slack, check out the documentation, or open an issue on the repository with the sample workflow.