You ship a small “safe” change on Friday. The diff is tiny, the tests are green, and the AI assistant was confident. An hour after deploy, your on-call channel lights up. A downstream service is rejecting responses that look fine in code review. Now you’re rolling back and rewriting a fix that should have been obvious if you had real traffic in the loop.
This isn’t a hypothetical. It’s happening at companies every week, and the pattern is consistent: we trust the output too early. The core failure isn’t the code. It’s the process that treats AI output as trusted before it is validated.
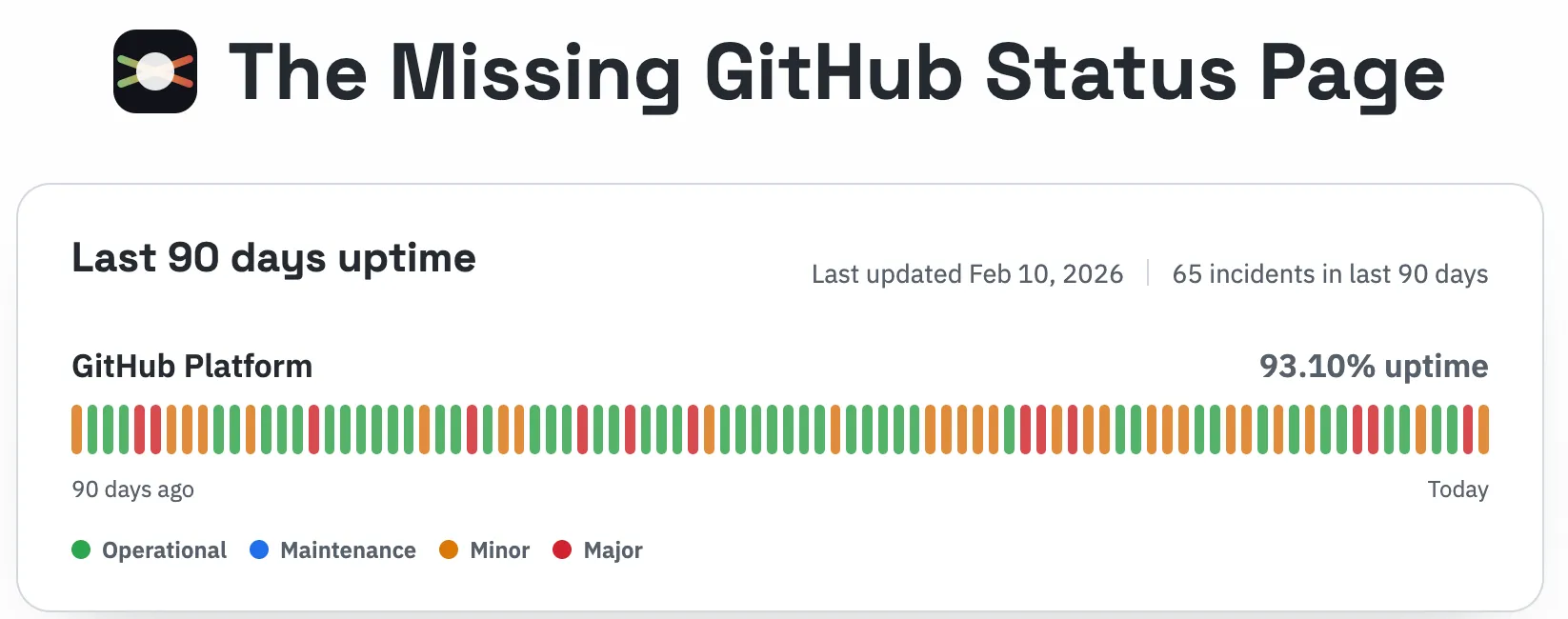
Developers are feeling the pressure to ship AI-assisted changes faster, and the frustration shows up publicly. When GitHub went down again, the HN thread lit up with reliability complaints and “vibe coding” jokes, plus links to a status mirror because the official page no longer shows aggregate uptime numbers. Lee’s take on the AI “vibe” problem is a good snapshot of that sentiment: AI Has No Vibe for Vibe.
At the same time, teams are being asked to ship faster with less slack. That combination - faster shipping, leaner teams, and more AI-written code - is exactly where silent failures show up, and where reliability can slip.
Teams are shipping code faster than ever, but production stability isn’t keeping pace. When AI is writing more of that code, the process needs to assume the output is untrusted until proven otherwise.
The Trust Gap Is Procedural
Silent failures happen when AI-generated code passes all static checks but breaks at runtime because it has not been validated against production reality. The code compiles, the tests pass, and the linter is happy. The failure is not just in the code. It is in the process that treats AI output as trusted before it is validated.
Early studies and real-world reports suggest AI-generated code can carry higher defect rates. CodeRabbit’s State of AI vs Human Code Generation report found AI-generated PRs contained about 1.7x more issues overall. See the CodeRabbit report. If throughput goes up while issues per PR also rise, defects can accumulate faster. That is the core risk: we are increasing speed without increasing skepticism.
Treat AI Output as Untrusted
AI coding tools are trained on public code. They have never seen your production traffic, your real API contracts, or your operational quirks. That gap will always exist. The only fix is a process that treats AI output as untrusted and forces it through stronger validation before merge.
Why Static Analysis Isn’t Enough
Tools like SonarQube, ESLint, and Qodo are good at catching syntax errors, code smells, and known vulnerability patterns. They answer the question “is this code well-formed?” But they can’t answer “does this code behave correctly with real traffic?”
Static analysis operates on code in isolation. It can tell you that a variable might be null. It cannot tell you how production traffic actually behaves, and that is where AI-authored regressions hide.
This isn’t a criticism of static tools. They catch real bugs. But they’re solving a different problem. Static analysis and runtime validation are complementary, not competing. You need both.
A Calibrated Validation Pyramid
Block published a testing pyramid for AI agents that flips the way we think about confidence. The layers are no longer just test types. They represent how much uncertainty you are willing to tolerate. See: Testing Pyramid for AI Agents.
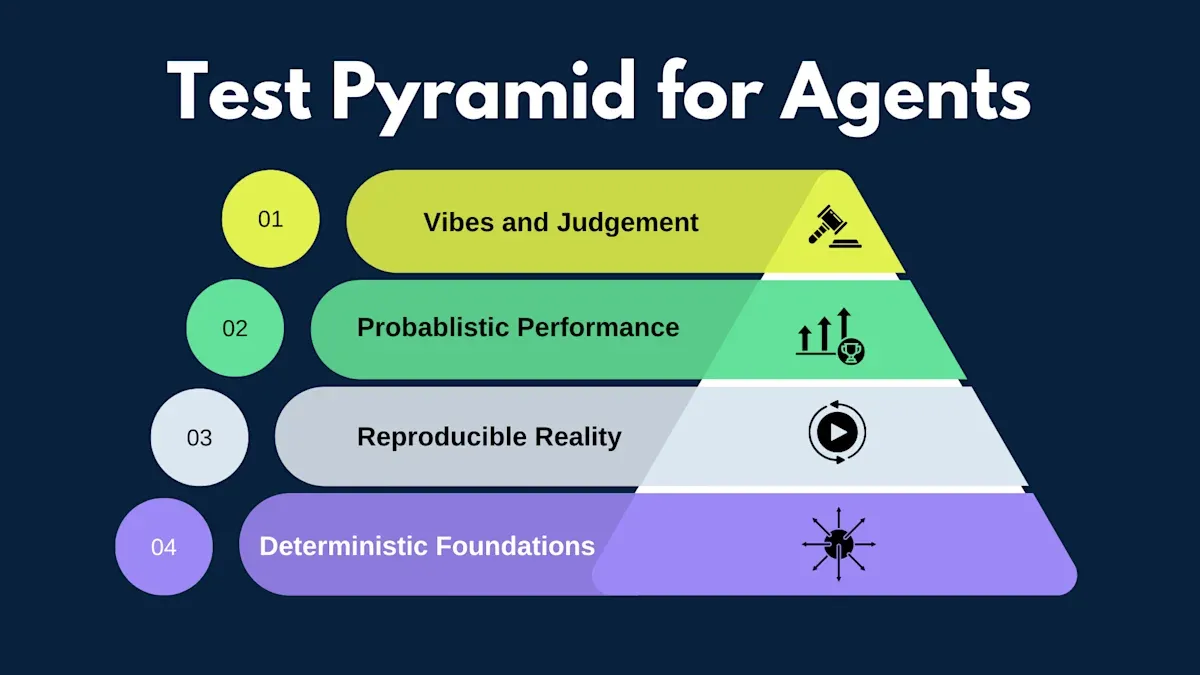
For AI-authored code, a similar pyramid helps keep trust calibrated:
- Deterministic base: fast, strict tests for logic, retries, input validation, and tool contracts. These should never be flaky.
- Reproducible middle: record real traffic once, then replay it deterministically to validate flows and dependencies.
- Probabilistic top: run repeated evaluations and look for success rates, not identical outputs.
- Human judgment: when success is subjective, make judgment explicit with rubrics and reviews.
The goal is not to slow down AI coding. The goal is to make the review process honest about uncertainty.
Process Checklist: Treat AI Output as Untrusted
If you want to avoid silent failures, make the process explicit:

- Gate by evidence: AI output does not ship without deterministic tests and recorded traffic replay.
- Fail fast on deltas: Block merges when behavior changes are detected, even if the diff is small.
- Replay before review: Run traffic replay before human review so reviewers see real behavior, not just code.
- Track uncertainty: For probabilistic outcomes, require repeated evals and document the acceptance threshold.
- Escalate risky scopes: Anything touching auth, payments, or data contracts gets stronger validation by default.
How Speedscale Catches What AI Misses
Speedscale captures production API traffic and replays it against code changes in your CI/CD pipeline. When an AI coding tool generates new code, Speedscale’s AI code verification tests it against real production scenarios before it reaches users.
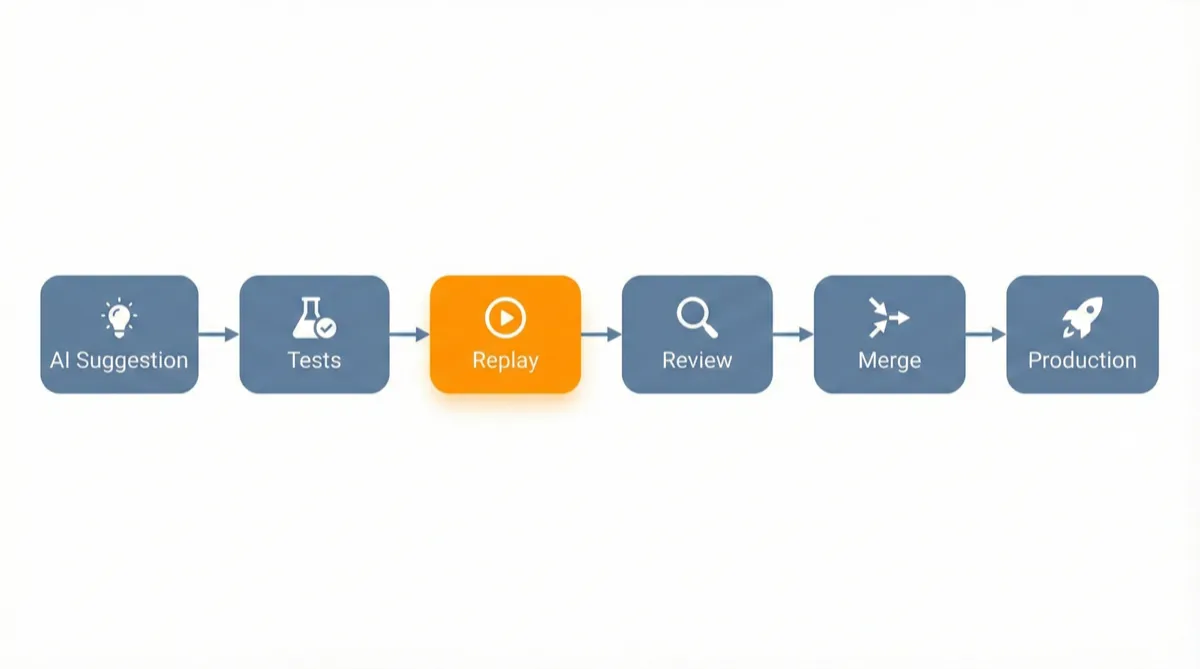
With Proxymock and MCP integration, AI coding agents can even access production signals while generating code. Instead of guessing at API contracts and data shapes, the AI can see actual traffic patterns and generate code that handles real-world edge cases.
Here’s what that looks like in practice:
- Your team uses Cursor to generate a new API endpoint
- Speedscale replays captured production traffic against the new endpoint
- The replay catches that some requests include a field the AI didn’t handle
- You fix the edge case before merging
- Production stays stable
Less reliance on staging. No synthetic test data to maintain. Just real traffic proving your code works.
Getting Started
If your team is adopting AI coding tools, runtime validation should be part of your workflow. The faster AI generates code, the faster you need feedback on whether that code actually works.
Start by capturing traffic from one production service and replaying it in your CI pipeline.
If you want a deeper view of the input side of this problem, read What AI Has Never Seen: The Context Gap in Code Generation.
For teams looking to validate AI-generated changes live, see the Speedscale demo.
Frequently Asked Questions
Does runtime validation replace unit tests?
No. Unit tests verify individual functions work as designed. Runtime validation verifies that the entire service behaves correctly with real production data. They test different things and catch different bugs.
How is this different from integration testing?
Integration tests use synthetic data and pre-configured test environments. Runtime validation uses actual production traffic patterns. The difference is coverage: production traffic includes edge cases that no one thought to write a test for.
Can runtime validation work with microservices?
Yes. Speedscale captures traffic at the service boundary, so each microservice can be validated independently against its actual production traffic. This is especially valuable for teams running 50-200+ services where maintaining test environments is expensive.