Preventing PII in Test environments
Data privacy and security are a top concern for most organizations. It’s easy to see why given changes over the past few years.
- According to IBM’s long running Cost of a Data Breach report, the average data breach costs global companies $4.35M. For US companies, the total more than doubles to $9.44M.
- The EU’s General Data Protection Regulation (GDPR) allows for penalties of up to 2% of a company’s worldwide revenue
- The California Privacy Rights Act of 2020 (CPRA) allows up to $7500 per willful violation
These types of protections can be great for us as consumers. However, they also make it extremely difficult to create realistic production simulations in pre-production. It’s hard to rapidly develop new applications if you can’t iterate against realistic data.
How was this solved in the past?
The discipline of Test Data Management was invented to safely replicate production data. These solutions would replicate a production database and anonymize questionable data along the way. The process tended to be run on a schedule and take a long time to finish. Additionally, data tended to grow stale and schema changes were discouraged by necessity. Nonetheless, this worked ok for the first generation web applications where data was relatively static and tended to stay put.
Modern Cloud applications tend to have a variety of services, data stores and APIs. Many of these services don’t have a simple replication mechanism. For example, how can you replicate the data in Salesforce when you don’t own that data store? Attempting to copy/paste data stores is simply too slow and limited for agile development.
How should an SRE or tools team supporting a modern Cloud application provide realistic production-like test data?
What information should be protected?
Most privacy rules emphasize protecting Personally Identifiable Information (PII). PII could be any information that identifies an individual. That’s a long list but here are a few examples:
- Full name
- Social Security Number
- Date of Birth
- Address
- Phone numbers
If you work in a highly regulated industry like financial services or healthcare there’s even more to concern yourself with. The Payment Card Industry Security Standard requires companies to protect additional information such as credit card numbers and security codes. Healthcare companies must contend with the Health Insurance Portability and Accountability Act** which raises the bar even higher. Depending on your organization’s interpretation of the GDPR, you may even need to anonymous second order identifiers like customer IDs.
How to prevent PII from leaking into pre-production
At Speedscale, we use recorded traffic to automatically produce a living, breathing simulation of production, including dependent APIs. You can learn more about that here.
As part of the recording process, we redact sensitive and personally identifiable information while capturing traffic. This is a streaming approach to DLP. That means data is always up to date, fresh and most importantly - anonymized. Redaction happens before traffic leaves your network, and the original sensitive data cannot be recreated. View our Data Loss Prevention page for more details.
What follows is a tutorial on how to enable data loss prevention for your Speedscale collector.
Prerequisites
Viewing traffic
Since we are capturing traffic from our service, we can observe individual request data in the traffic viewer. When we drill down into requests, we can see that we are capturing some sensitive information such as an API key in the authorization header for a request to a third party.
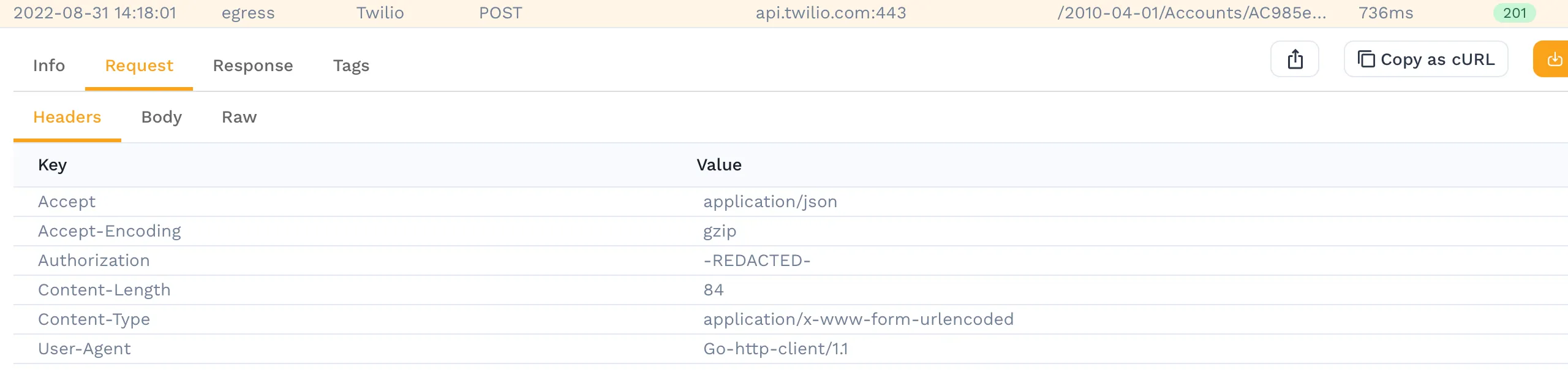
Although we can manipulate this during a replay using transforms, we may not want to ever capture this data or let it leave the cluster. This is where Data Loss Prevention comes in. We can configure the Operator to redact this data.
Configure Data Loss Prevention
Navigate to the DLP config section and select the standard config. Here you can see that the standard config comes with a default set of fields to redact such as authorization, apikey, jwt and so on. If you want to make a custom config, you can create your own.
Enable Data Loss Prevention
DLP is not enabled by default so you must configure it during or after installation. If you have installed via the Helm chart, you can see the corresponding values that need to be edited here:
Data Loss Prevention settings.
dlp: # Instructs operator to enable data loss prevention features enabled: false # Configuration for data loss prevention config: “standard”
Simply flip enabled: true and put in whichever config you want to use in the config field. If you installed the Operator via speedctl, you have to edit the speedscale-operator configmap in the speedscale namespace with kubectl -n speedscale edit cm speedscale-operator.
apiVersion: v1 data: CLI_VERSION: v1.0.130 CLUSTER_NAME: my-cluster DLP_CONFIG: standard IMAGE_PULL_POLICY: Always IMAGE_PULL_SECRETS: "" IMAGE_REGISTRY: gcr.io/speedscale IMAGE_TAG: v1.1.22 INSTALL_SOURCE: deploy INSTANCE_ID: 27128055-eac3-4238-bc2c-4044e14cffbf LOG_LEVEL: info TELEMETRY_INTERVAL: 2s WITH_DLP: “false” WITH_INSPECTOR: “true” kind: ConfigMap
Edit the fields WITH_DLP and DLP_CONFIG to the desired values and then make sure to restart the Operator in order for it to pick up on the new settings. This can be done via kubectl -n speedscale delete pod -l app=speedscale-operator.
Confirm redaction
After making this change, we can see for the same request that the field has been redacted. This happens at the Operator level and not in our cloud sytem so the Authorization header value never left your cluster and was never seen by Speedscale.