Mastering Kubernetes Testing with Traffic Replay
Kubernetes has become the backbone of many modern application deployment pipelines, and for good reason as a container orchestration platform, Kubernetes automates the scaling, deployment, and management of workloads, allowing developers to make their applications easier to manage and deploy at scale without worrying about their service’s dependencies, their user’s operating system, or the intricacies of their data center or infrastructure provider.
The promise of Kubernetes - ship faster and operate at a larger scale - has caused an explosion of adoption across a wide variety of industries and use cases.
While Kubernetes is incredibly popular for these operational benefits, it does present some serious challenges in some particular areas. One of these areas - testing - is a core component of the continuous integration and deployment pipeline, which has so readily adopted it.
This has created a large amount of friction. The very features that make Kubernetes so powerful, such as distributed workloads, ephemeral containers, and dynamic scaling, also make it difficult to reproduce production conditions in test environments, creating a consistent point of conflict for teams.
Without realistic testing, even the most well-architected clusters can fail under real-world demands. That’s where traffic replay comes in, and why solutions like Speedscale are redefining how Kubernetes teams validate and use their systems in development.
In this article, you’ll find a practical guide to mastering Kubernetes testing with traffic replay, providing step-by-step insights and actionable strategies. Today, we’re going to take a look at why Kubernetes makes testing challenging and showcase how Speedscale can bypass many of these problems through traffic capture and replay. Let’s jump in!
Why Testing Kubernetes is Uniquely Difficult?
The problem with testing in Kubernetes is that there’s some fundamental misalignment between the Kubernetes approach and the approach to testing common in CI/CD pipelines.
Kubernetes is a dynamic system - pods are created and destroyed constantly, services scale up and down, and configurations often shift dynamically as deployments evolve. Testing in the CI/CD pipeline is based on several assumptions that invert this - they assume a static environment with predictable patterns and systems that can be tested and validated against. Integration tests, which evaluate the interaction between multiple components or services, are often designed for static environments and may not align well with Kubernetes’ dynamic nature.
This creates a high amount of friction between Kubernetes and the testing process, and this friction can generate a lot of complexity that can be hard for providers to manage. These factors mean that static test data or simple synthetic requests often fail to expose the issues that appear in production. This can generate some common challenges.
Ephemeral Environments
While containers may only exist for seconds or minutes, testing requires consistent testing data captured over time.
Service-to-Service Complexity
Microservices usually communicate over both internal and third-party APIs, which can be difficult to mock accurately. In these scenarios, a client is often used to interact with Kubernetes resources, manage namespaces, and perform queries during testing, which adds another layer of complexity.
Scaling Unpredictability
Auto-scaling and load balancing can change how workloads operate under realistic load, meaning your mocks may lock you into a specific behavior that is inconsistent and potentially unrealistic.
The impact of scaling and load balancing on workloads can only be accurately measured by observing real-world performance metrics during testing.
Configuration Drift
Over time, cluster configurations can change, creating a divergence from testing to production, which introduces significant new risks. Changes in the definition of cluster configurations—such as updates to parameter definitions or configuration file entries—can introduce additional risks and complicate testing efforts.
The Problem with Synthetic Testing
For many providers, the solution might seem obvious: just deploy synthetic testing and call it a day. Unfortunately, synthetic testing is less helpful in this context. While pre-scripted HTTP requests and mocked data flows can be useful for functional testing, they fall short when the goal is production-grade confidence. Synthetic tests often fail to produce the expected outcomes that occur in real production environments, leading to gaps in reliability and correctness.
Without production-like traffic, teams miss a wide variety of patterns and systems.
Real API Call Patterns
Kubernetes systems often have a lot of distinct API patterns and interactions that are hard to replicate with synthetic data. There are the obvious culprits, such as management systems integrated into the Kubernetes API, but also less obvious timing and synchronization concerns arising from the Kubernetes control plane, configuration data, specific cloud storage providers, interactions with external container orchestration tool compatibility layers from third parties, and more.
This is often reflected neatly in observed data, but can be missing unless you intentionally rebuild these interactions in your synthetic data systems, which introduces a significant amount of top-heavy processing and time-consuming scoping and buildouts.
Actual Load Distribution
When you dive into synthetic testing, there’s a tendency to consider everything on an equal playing field, but in Kubernetes, this is just not true. When you have blended systems of different cloud providers, persistent storage mixed with ephemeral solutions in a complex storage system, multi-cluster management, and container runtime endpoints feeding data actively, and an API server trying to orchestrate all of this, your system will have endpoints with wildly different endpoint loads.
In synthetic testing, treating these endpoints as equally balanced can reflect an inaccurate state that may actually harm your testing and development process holistically. Additionally, the output of synthetic testing may not accurately reflect the true performance and behavior of endpoints under real-world conditions.
Dependency Timing
Even if some data reflection is inaccurate, dependency timing can be a significant issue in Kubernetes systems. Network latency spikes and slow downstream services, especially across complex systems and storage resources, can result in timing issues that are hard to replicate in testing data.
This is a significant aspect of infrastructure management, particularly with complex relational computing resources. Dependency timing issues can only be represented with actual data, and thus, synthetic data often falls woefully short.
It is essential to verify that all dependencies are ready and functioning as expected to accurately assess timing-related issues in Kubernetes systems.
Kubernetes-Specific Attributes
Kubernetes architecture introduces some specific attributes that can create particular complexities that must be managed at scale. Kubernetes objects represent a persistent state that can be referenced and interacted with, while the container images and the Kubernetes service that they create are ephemeral. One is necessarily more active than the other, but their static and ephemeral natures fundamentally reflect a difference in state and interaction.
Testing must also account for the interaction between various components, such as Kubernetes objects and services, to ensure comprehensive coverage of how these parts work together within the system.
In other words, creating static data for testing is a snapshot of a system that is constantly changing by its very nature. No export of a configuration file or replication of a container registry can accurately represent the true nature of a Kubernetes cluster at scale, and achieving this is a running task that can never be fully completed.
What Traffic Replay Brings to the Table?
An alternative approach to replicating in synthetic data is to utilize the actual data from your service. A good process for this is Traffic Replay.
Traffic replay is the process of capturing traffic, the actual requests and responses from your API server and the constituent parts in the network, and then using that data in a replay to test, stage, and iterate. This method allows teams to run tests with real captured traffic, improving the accuracy and reliability of their testing efforts.
This approach has some key advantages.
Realism
Every request matches production, including edge cases you didn’t anticipate. This represents both your containerized applications as well as the network and cloud infrastructure in which they operate, allowing you to represent the production environment and traffic without exposing the actual production systems to risk.
Traffic replay enables validation of the complete functionality of containerized applications in a production-like environment.
Reproducibility
Bugs that only appear under certain request patterns can be replayed for consistent debugging. Everything from issues around resource utilization to delays in transit between Kubernetes clusters can be accurately discovered, reproduced, and mitigated because you are using the actual incident for the process.
Using assertions during replay helps confirm that previously identified issues have been resolved and that resources are in the expected state.
Performance insight
Identify slow endpoints, bottlenecks, and scaling limits using real data flows. Kubernetes services are particularly sensitive to specific issues that may not overlap with standard network proxy, connectivity, or infrastructure problems. However, traffic capture and replay can address this, as it allows for capturing everything and testing specific aspects in isolation.
Unlike traditional load testing, traffic replay doesn’t just measure throughput - it tests how your system behaves under your exact production conditions.
How Speedscale Delivers Traffic Capture and Replay
With all of this in mind, how does Speedscale offer these benefits to providers? Speedscale specialises in making traffic replay practical for Kubernetes environments, unlocking powerful observability, custom metrics, and top-level awareness. Its platform integrates directly with your cluster to capture real traffic without impacting production performance. Speedscale also works alongside other tools to provide comprehensive testing and observability in Kubernetes environments.
Traffic Capture
Speedscale offers powerful traffic capture through sidecars, ingress controllers, and network taps, allowing you the ability to record inbound and outbound requests across multiple containers, mixed cloud and local storage, blended applications, and multiple cloud providers.
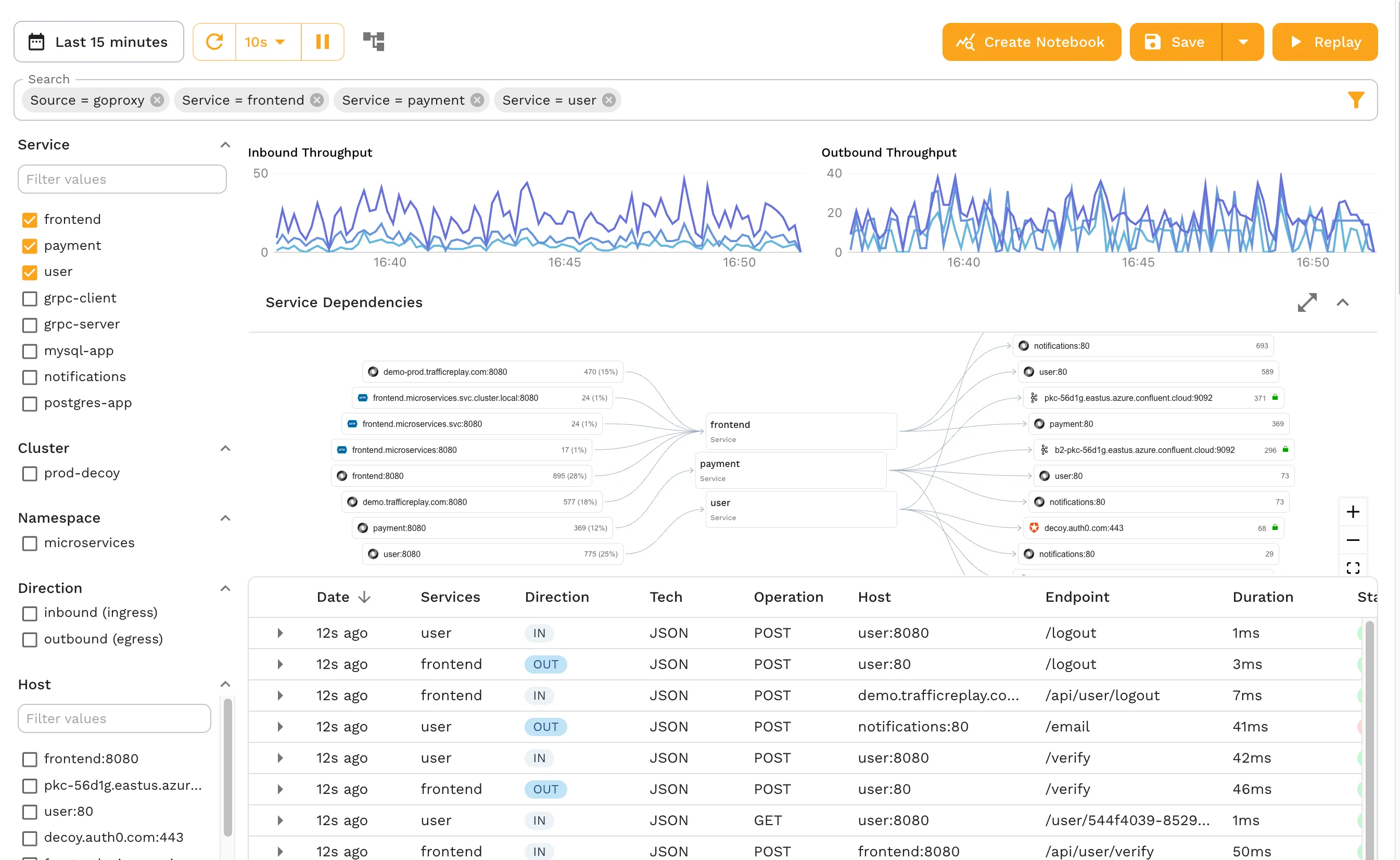
This powerful capture process can give you a great view of even the most complex of containerized apps and ecosystems, unlocking cloud native development and Continuous Integration/Continuous Delivery processes at scale.
Replay Scenarios
When you have this data in hand, Speedscale also makes it easy to replay that data, allowing for targeted testing across diverse goals, including load, regression, or chaos experiments. Replay scenarios can be run against applications and services that are already deployed in the Kubernetes environment.
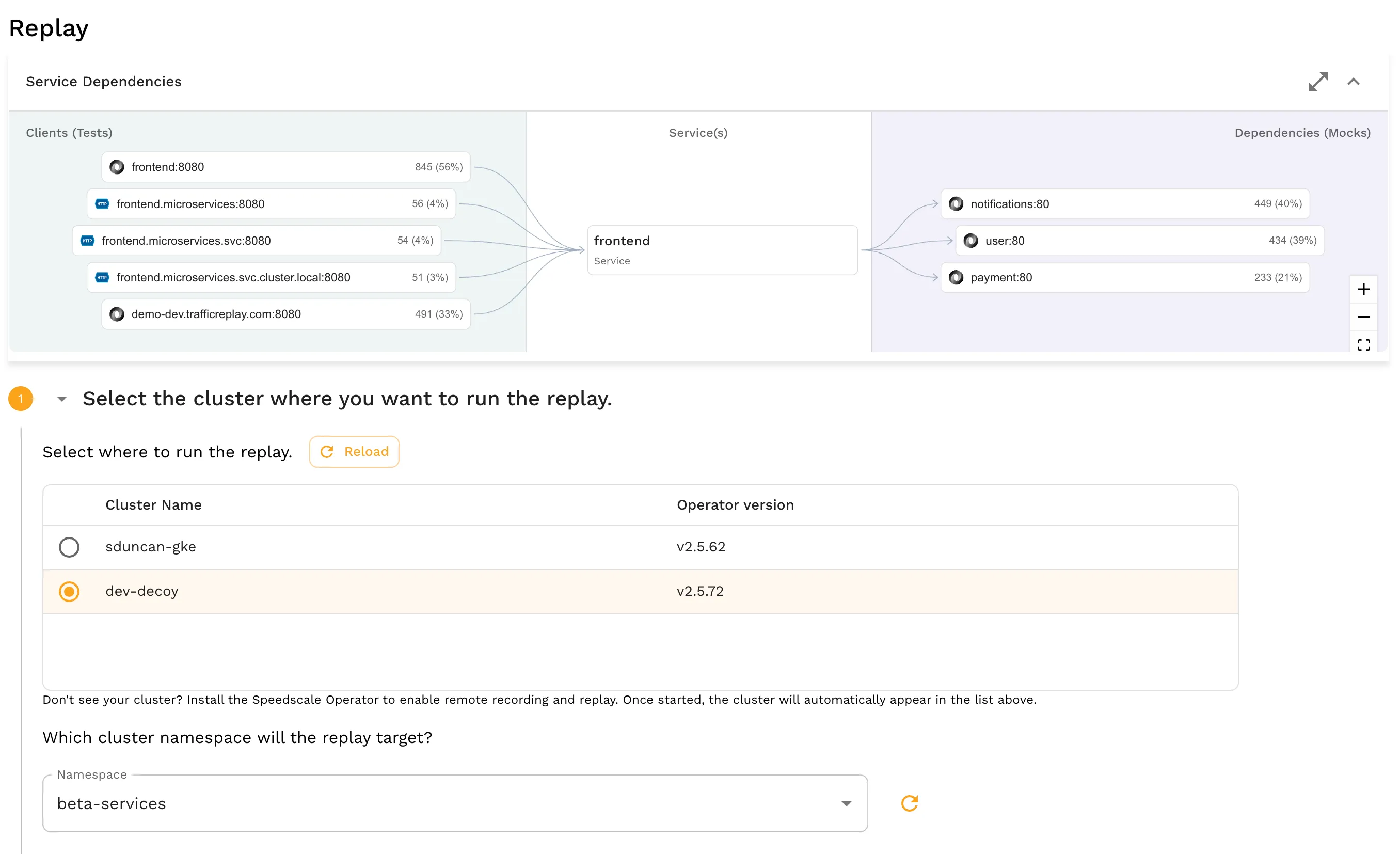
By using real data, you can deploy with minimal downtime, as in zero downtime, while ensuring you are able to test load balance or data management processes. This helps with scaling containerized applications while mitigating the typical restrictions faced in that process.
Data Safety
Any good Kubernetes operator is concerned about compute and data safety. Traffic capture and replay is a key component in effective resource availability for testing, while ensuring adequate safety, and Speedscale offers additional controls through filtering to ensure that you’re only capturing what you actually need to do the work you need to do for testing.
You can filter down by data types, control what data is pulled from your container image and Kubernetes environment, and even customize data collection through filters to target one or more containers (or multiple applications split between containers).
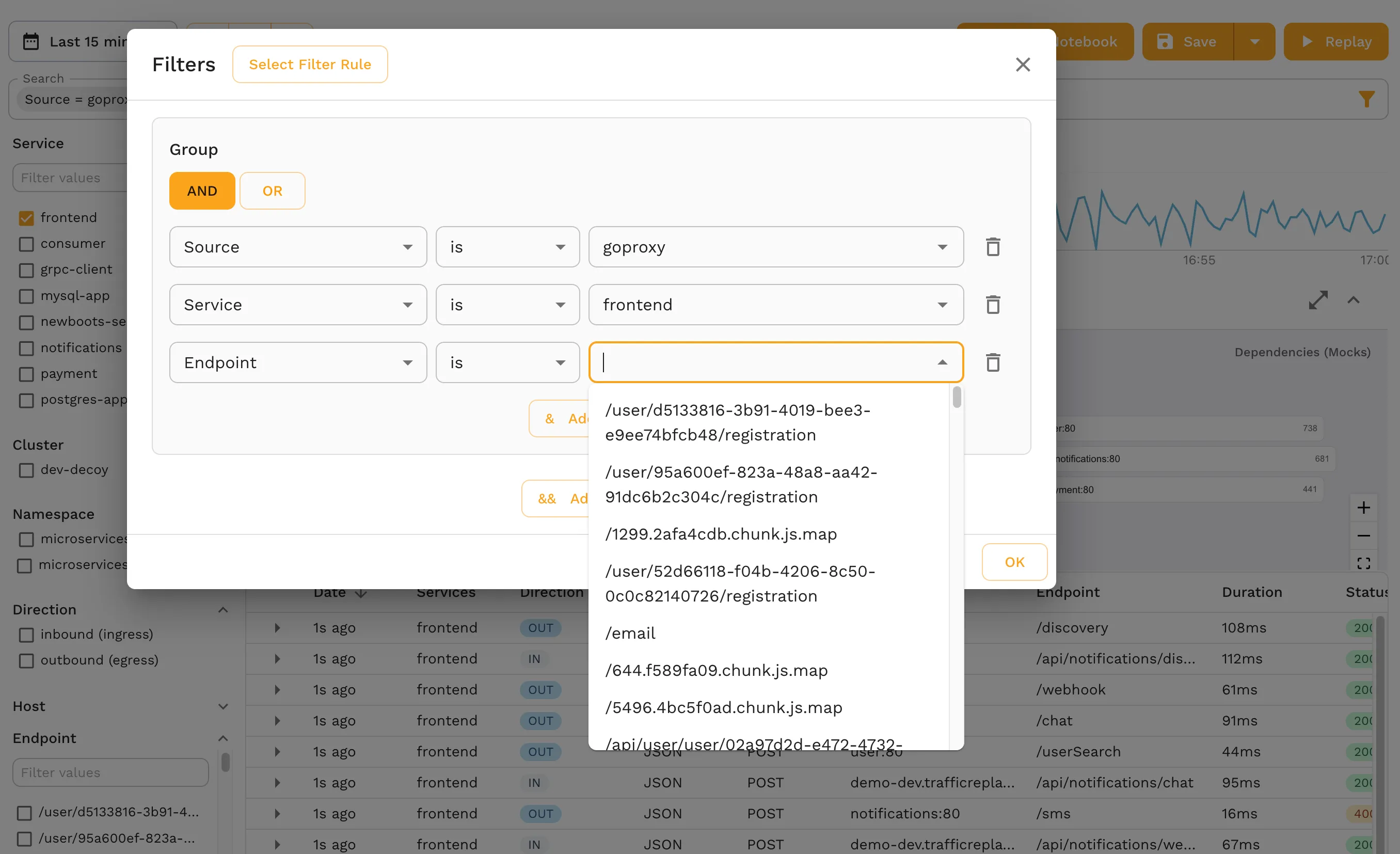
For serverless Kubernetes installations, you can make your data collection capture traffic as a middleware system, thereby providing value without having to change your entire architecture and control plane.
Integrating security testing with traffic replay helps identify vulnerabilities and ensures compliance with data protection standards.
CI/CD Integration
Speedscale has world-class CI/CD integration, allowing you to capture data and integrate that data into your process seamlessly. Run replay tests as part of your deployment pipeline to catch issues before they reach production, and then use capture to ensure that the fix does what you think it does outside of just a single instance or a synthetic testing environment!
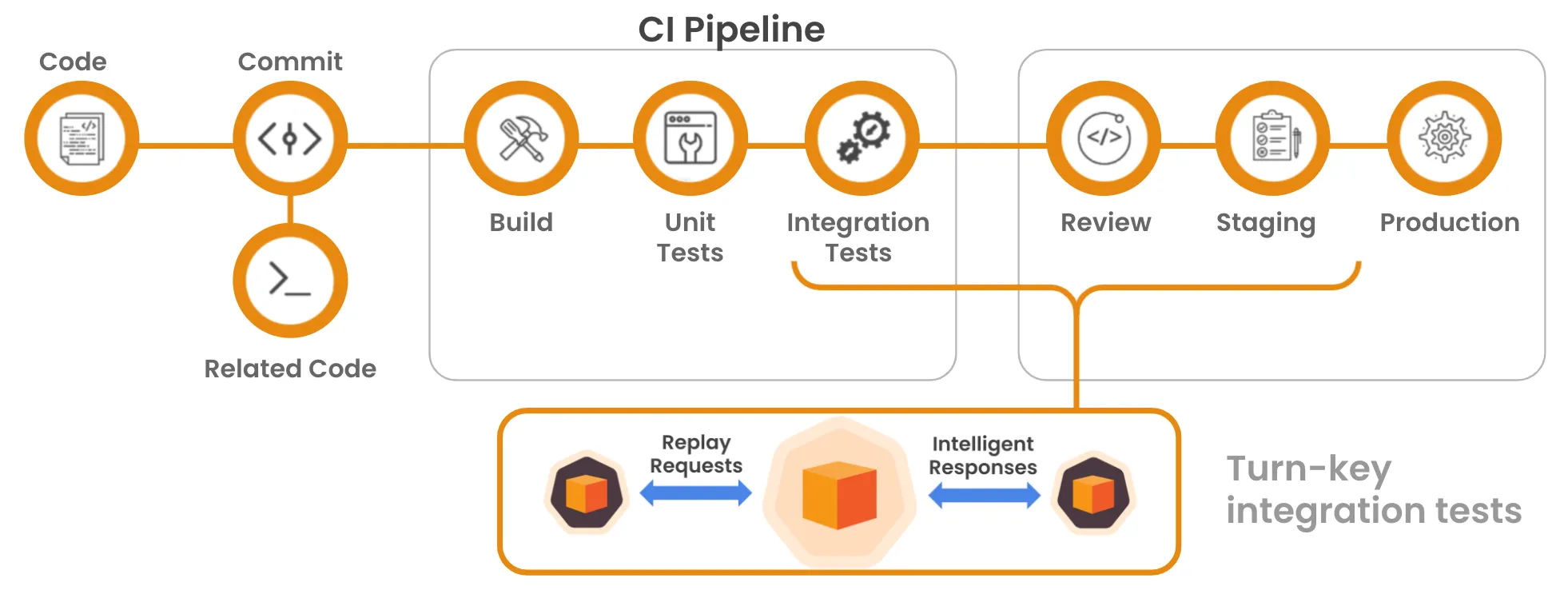
Additionally, monitoring the results of tests run during CI/CD integration helps ensure that deployments meet quality and reliability standards.
Real-World Impact
Teams adopting traffic replay with Speedscale have uncovered critical issues that traditional testing missed. Examples include:
- Detecting API contract changes that would have broken downstream services.
- Identifying a scaling misconfiguration that caused performance degradation under specific load bursts.
- Preventing a failed deployment by replaying high-volume Black Friday traffic patterns against staging.
By reproducing production conditions in a controlled environment, these teams avoided outages and costly rollbacks. Preventing these issues results in significant cost savings for organizations, as unplanned downtime and rollbacks can greatly increase operational expenses. Speedscale can have huge impacts - everything from ensuring efficiency with a public cloud, mitigating drift for configuration details, and managing traffic flow involving the Kubernetes master node and groups of containers vying for CPU usage on the same network is made that much easier with real data traffic and replay at scale.
Best Practices for Traffic Replay in Kubernetes
To get the most from traffic replay, follow these guidelines:
It is important to define the scope of traffic replay to ensure all critical components and scenarios are included, providing comprehensive test coverage.
Capture Representative Traffic
Replay is only as good as the data you feed it. If your captured traffic doesn’t reflect actual usage patterns, you risk building false confidence in your system. This means capturing sessions that include peak load periods, off-hours traffic, unusual request bursts, and rare edge cases. For example, a holiday shopping weekend might reveal different scaling behaviors than a regular weekday morning. By ensuring your sample contains both the routine and the exceptional, you’ll catch issues that only appear under specific conditions.
Teams should begin by capturing a small, representative sample of traffic before expanding to larger datasets. This approach helps identify issues early and allows for gradual scaling of testing efforts.
Sanitize Sensitive Data
Production traffic often contains sensitive information such as personally identifiable information (PII), payment card data (PCI), or health-related records. Before replaying any captured data, it’s critical to apply masking or anonymization. This can be done with field-level redaction, tokenization, or synthetic data replacement. Not only does this protect user privacy and meet compliance requirements, but it also prevents accidental exposure of regulated data in lower environments. Remember, staging should feel like production in load and complexity, but never in data sensitivity.
Utility functions can be leveraged to automate the sanitization of sensitive data before replaying traffic.
Test Regularly
One-time testing provides a snapshot of your system’s health, but Kubernetes clusters are dynamic. Service updates, dependency changes, and even infrastructure drift can all introduce new risks over time. By scheduling replays on a recurring basis - whether nightly, weekly, or tied to your CI/CD pipeline - you maintain a continuous view of your application’s performance under realistic conditions. This ensures that regressions and misconfigurations are caught early, before they affect end users.
Automated replay processes can be developed to maintain ongoing validation of application performance.
Combine with Chaos Testing
Traffic replay excels at recreating known scenarios, but real-world outages often involve unpredictable failures. By layering controlled chaos experiments, such as pod terminations, network latency injection, or simulated node failures, into your replay sessions, you can see how your application behaves when both traffic and infrastructure are under stress. This combination testing helps validate that your system not only works when everything is healthy, but also remains resilient when something goes wrong.
This approach enables end-to-end validation of system resilience under both normal and failure conditions.
Conclusion – Production Confidence Without the Risk
Kubernetes testing doesn’t have to be guesswork. By leveraging real traffic capture and replay, teams can validate deployments against the exact conditions they’ll face in production, without risking customer impact.
As complex machine learning and LLM systems become more ubiquitous, especially those using complex services with blended API Objects, managing containerized applications is going to become ever more important. Isolating services on the same node, managing complex DNS server configurations, and optimizing your Kubernetes controller manager can all be significantly improved and simplified with a solution like Speedscale.
Speedscale’s approach brings this capability directly into the Kubernetes workflow, helping teams ship faster, safer, and with more confidence. Without being tied to synthetic testing or identical pods for ease of management, the Kubernetes community can now test and develop without limitation. This allows for the establishment of a quality control loop that offers a web UI, a command line interface, and a bespoke developer experience that is peerless in the market.
If your testing still relies on synthetic data, traffic replay may be the missing link between staging success and production reliability. Consider integrating traffic replay into your project to improve testing and deployment reliability. Try out Speedscale today!