Everyone wants an AI agent factory in 2026. Autonomous agents fixing bugs and shipping features while you sleep. I’ve been building toward that myself.
But the error rates don’t support the fantasy. The best AI coding agents in the world fix about 50% of real bugs on SWE-bench verified. Half the time they fail. And AI-generated code produces 1.7x more issues than human-written code. We’ve written about this before: agents silently breaking working systems, dark code nobody understands, the context gap between training data and production.
More errors, arriving faster. That’s the actual trajectory if you don’t change the inputs.
The agent tooling vendors are working on prevention. Skills, hooks, MCP plugins, guardrails. Those help stop new errors from happening. But when an agent is fixing a bug that already exists in production, it needs something different. It needs to know what’s actually happening on the wire. I wanted to measure exactly how much that matters, so I built a benchmark to test it.
240 microservices the model has never seen
A fictional multi-tenant LLM gateway called Helix. 240 microservices across four languages (Go, TypeScript, Python, Java), organized the way a real enterprise platform would be: edge proxies, provider adapters, tenant management, caching layers, data pipelines, admin tooling. About 65,000 lines of code. None of it was ever published or indexed.
I injected 100 hand-authored bugs across the services. Schema gaps between types and wire payloads, missing headers, SSE framing errors, race conditions, URL encoding mismatches, exception handling mistakes. The kinds of bugs that show up in production when somebody refactors a normalizer and forgets that the wire format uses snake_case.
Each bug has a deterministic test. The agent’s fix either makes the test pass or it doesn’t. The test files aren’t in the working directory, and the agent can’t read them. All it gets is a verify script that outputs PASS or FAIL.
Datadog alert vs. traffic capture: the A/B test
This is the comparison I actually cared about.
Condition A: what Datadog gives you. The agent gets a monitoring alert. Error rates, metric graphs, affected services. This is what that looks like:
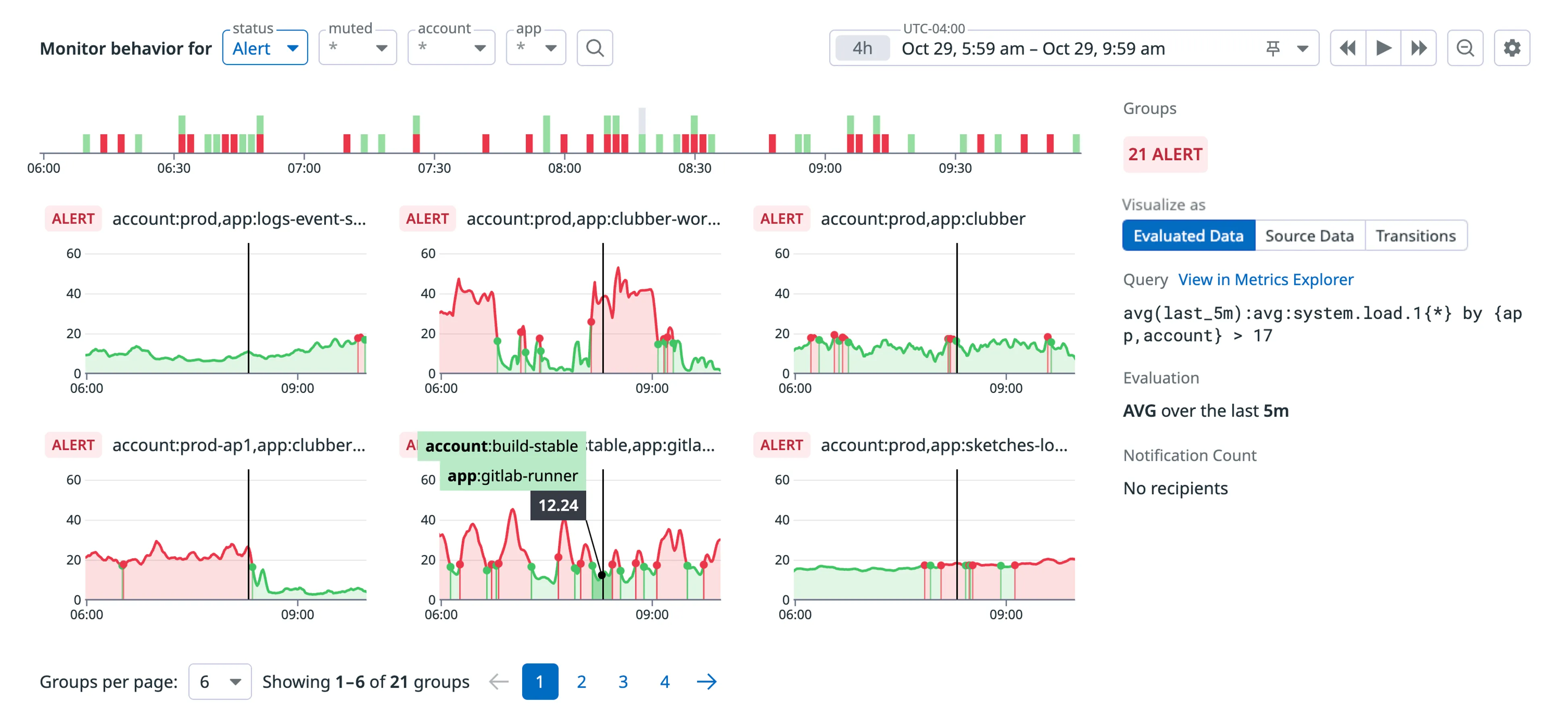
21 alerts, six graphs, no request bodies, no response payloads. The agent gets the full 240-service codebase and has to figure out which service is broken, find the buggy file, fix it, and verify. No hints about which service or language the bug is in.
Condition B: what Speedscale gives you. Same codebase, same verify script. But instead of metric graphs, the agent gets a detailed bug report and captured request/response pairs showing the actual failure on the wire. The captures show what the client sent, what the server returned, and where the two diverge.
Same model (gpt-5.4-mini), same timeout (10 minutes), same agent framework (opencode). The only variable is whether the agent has traffic context.
51% vs. 77%
| Condition | Pass rate | 95% CI |
|---|---|---|
| Alert only | 51% (51/100) | [41, 61] |
| Alert + traffic captures | 77% (77/100) | [68, 84] |
+26 percentage points. The confidence intervals don’t overlap.

The agent greps 240 directories and guesses
The pass rates tell one story. The agent’s logs tell a better one.
In condition A, the agent gets an alert like “P99 latency increased on /v1/embeddings” and has to figure out which of 240 services is responsible. It starts by grepping the codebase for keywords from the alert. Sometimes that works. The alert mentions “streaming” and the agent finds sse-relay on the first try. But usually the keywords are too generic. “Error rate” matches half the codebase. “Latency” matches everything. The agent reads one service, decides it’s not the bug, moves on, reads another. The median solve time for condition A was 93 seconds. The 75th percentile was over two minutes.
In condition B, the agent reads the captured traffic, sees that the response body has a null stop_sequence field when the wire payload clearly contains one, and greps for “stop_sequence” across all services. It finds the normalizer in 20 seconds, reads the struct, sees the missing field, patches it. Median solve time: 46 seconds. Half the wall clock of condition A.
The biggest time sinks in condition A were the searches, not the fixes. The agent would spend 90 seconds reading the wrong service’s source code, then 30 seconds actually fixing the bug once it found the right one.
34% of the time it picked the wrong service
Of the 100 bugs, 40 passed both conditions and 12 failed both. That leaves 48 bugs where the two conditions diverged.
37 of those were rescues: the agent couldn’t fix the bug from the alert alone, but the traffic captures pointed it to the right place. 11 went the other way. Net +26pp.

The wrong-service rate tells most of the story. In condition A, the agent went to the wrong service 34% of the time. It had to grep across 240 directories with a vague alert and guess which service was broken. In condition B, the wrong-service rate dropped to 4%. The captures contained enough information about the specific endpoint, the specific field, the specific response shape that the agent could narrow the search almost immediately.

25 of the 37 rescues were cases where condition A went to the wrong service entirely but condition B didn’t. The other 12 found the right service in both conditions but only condition B produced a fix that actually passed the test. Captures didn’t just help with navigation. They helped the agent understand what the fix should look like.
Even when it finds the bug, captures make it 2x faster
Even on the 40 bugs where both conditions passed, captures made the fix faster. Condition A averaged 103 seconds. Condition B averaged 53 seconds. 2x.
The reason is search cost. Without captures, the agent has to read code to build a mental model of what the service does and where the bug might be. With captures, it already knows what the wire format looks like and can skip straight to the code that handles it.
One example that stuck with me: bug 072 (SSE reconnect with stale last-event-id). Condition A spent 8 seconds, went to the wrong service, and gave up. Condition B solved it in 25 seconds because the capture showed the last-event-id header being dropped on reconnect. The agent grepped for “last-event-id,” found the SSE client code, saw the missing header copy, and patched it. The capture turned a needle-in-a-haystack search into a targeted lookup.
When traffic context makes the agent worse
11 bugs went the other way: the agent fixed them without captures but failed with captures attached.
The behavioral data on those 11 is the interesting part. Without captures, the agent averaged 143 seconds and touched 3 files per bug. It was slow and exploratory, reading multiple source files before committing to a fix. With captures, it averaged 63 seconds and touched 0.9 files. It was fast and decisive. And wrong.
The captures gave the agent a theory. When the trace shows an HTTP request with a specific header, the agent walks straight to the handler that processes that header and edits it. It doesn’t keep exploring. But on these 11 bugs the actual fix was somewhere else: an exception base class two layers down, a type hierarchy the HTTP trace can’t see, or a sort function that mutates its input. The capture pointed at the right symptom but the wrong layer.
Without captures, the agent had no strong theory. It read more code, tried more things, and eventually found the real bug through exploration. The captures replaced that exploration with confidence, and the confidence was misplaced.

Four of the 11 were exception-class bugs (wrong error type, wrong subclass in a catch block). The HTTP trace shows a 500 with a message, but the fix is in an error class definition that never appears in the trace. The agent sees the 500, goes to the handler, edits the handler. The real bug is in an error utility file the agent never opens.
When to give your agent traffic and when to skip it
The 51% baseline matters. This codebase has never been in any training set. The model has genuinely never seen it. In a public repo the baseline would be higher because the model has already memorized the codebase, the commits, the issue threads. That inflated baseline would make captures look less useful than they are. The +26pp lift we measured is against a clean zero-shot baseline, in a 240-service codebase where the agent has to find the right file before it can fix anything.
The practical takeaway: attach traffic captures when the bug depends on what’s actually on the wire. Wrong field names, broken SSE framing, header mismatches, URL encoding issues, schema drift between the type system and the JSON payload. These are the bugs where the agent’s improvement was largest because the answer literally lives in the captured bytes.
Don’t rely on captures when the bug is in an internal transformation layer. Exception hierarchies, race conditions in internal state, normalization logic that’s several function calls below the HTTP boundary. The captures will make the agent faster and more confident, but confident in the wrong direction.
An AI agent with a Datadog alert and 240 microservices goes to the wrong service a third of the time. A third of your agent’s budget, wasted reading the wrong code. Traffic captures cut that rate to 4%. That’s the difference between an agent burning ten minutes on the wrong service and one that finds the bug in under a minute.
Speedscale captures production traffic and makes it available to your coding agent as structured request/response context. If you’re seeing rework loops on bugs that hinge on what’s actually on the wire, try it here.
100 bugs across 240 microservices in a private, hand-authored codebase (Go, TypeScript, Python, Java). Never published; definitively not in any training dataset. Two conditions: alert-only (A) and alert-plus-captures (B). Agent: opencode with gpt-5.4-mini, 10-minute timeout per condition. Scored by test pass/fail. Wrong-service edits count as failures. N=1 per condition per bug. Full per-scenario data is internal.