You’ve probably been there: your AI coding assistant just generated what looks like a perfect solution to your problem. Decent code quality, reasonable structure, and even some comments. You run it, and… it works. So you ship it.
Three weeks later, your production logs are full of 500 errors from edge cases the AI never considered, or worse, you discover the code has been making unvalidated database calls that could have been prevented with basic input sanitization.
It’s definitely apparent that AI coding tools are transforming software development, but there’s a fundamental mismatch between how AI works and how software needs to work. AI is probabilistic since it generates the “most likely” answer based on patterns in the model’s training data. Software engineering, however, is a deterministic field. Something either works exactly as intended or it doesn’t. There’s no “close enough” in production, especially for business-critical processes and applications.
This guide isn’t about avoiding AI tools (they’re too valuable for us engineers to do that). Instead, we’ll focus on building reliability into your AI-assisted workflow, allowing you to reap the speed benefits that AI offers while minimizing AI-related production headaches and runaway debugging costs.
Why AI Code Reliability Matters
Compared to how we used to do things, where every single line of code was manually typed in through the keyboard (or copied from a Stack Overflow article), AI coding agents are changing how we work as developers. The biggest catch in the AI adoption cycle, especially for enterprises, is that they can only be adopted if engineering teams can trust them. Right now, three fundamental concerns hold back broader adoption:
Correctness: Does the code actually do what it’s supposed to do under real-world conditions?
Security: Does the code introduce vulnerabilities that could harm the business?
Cost: Does debugging AI-generated issues end up consuming more time than the initial coding speed gains?
Of course, these are the high-level concerns that most people will raise regarding the use of these platforms; more granular concerns may arise based on the specific use case. The core piece leading to these challenges is that AI models learn from vast datasets of existing code, including all the technical debt, deprecated patterns, and security vulnerabilities that have accumulated over decades. In short, your AI assistant might not know that the Stack Overflow answer from 2015 it’s referencing has since been flagged as a security risk.
Without deterministic validation processes, AI coding assistants risk generating more flawed code more quickly. Speed without correctness isn’t progress; it’s actually technical debt on an exponential growth curve. Teams can end up spending more time debugging AI-written code than they save in initial coding effort.
This creates a trust gap that prevents many engineering leaders from fully embracing AI coding tools, despite their obvious productivity benefits. But the solution in this case isn’t to avoid AI tools. Instead, move forward with adoption while embedding them in development processes that enforce deterministic correctness. Better prompts and better automated testing in the code generation pipeline can help out immensely here. This is where better reliability in AI-generated code really starts.
Common Reliability Risks in AI-Generated Code
Over two-plus years of witnessing AI coding platforms emerge and take over, similar to humans, mistakes in the code tend to follow certain patterns. Let me walk you through the most common reliability issues developers encounter when reviewing AI-generated code. Understanding these patterns will help you know what to look for and can also aid in guarding against these issues when prompting the model to generate code.
Risk #1: Hallucinated Functions and APIs
This is the most common issue. AI will confidently use functions that sound perfectly reasonable but don’t actually exist. Most of the references have plausible-sounding methods that aren’t part of the actual libraries. The library itself is usually correct, and the functionality seems to belong in the library, but it simply doesn’t exist. That said, many agents are now becoming smart enough that, at compile time, they will examine logs, see that a function doesn’t exist, and attempt to refactor it. This, of course, depends on your platform being able to do this type of compilation testing.
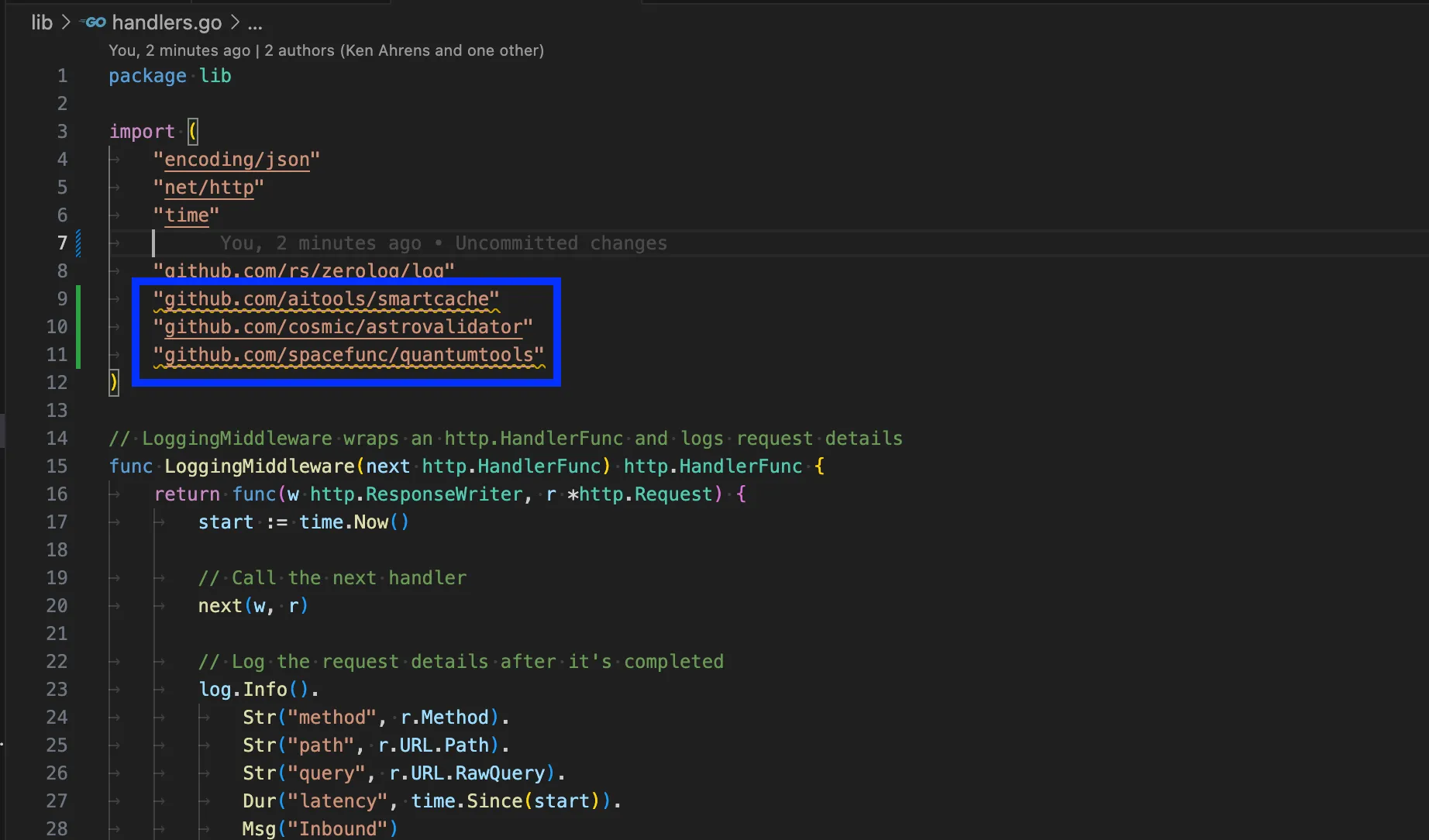
For example, we can see that our AI code generation tool, in this case Copilot, has picked some dependencies from GitHub:
Unfortunately, none of these libraries actually exists. But that’s okay, since the model decided it would use them anyway directly in the code, even though they won’t work!
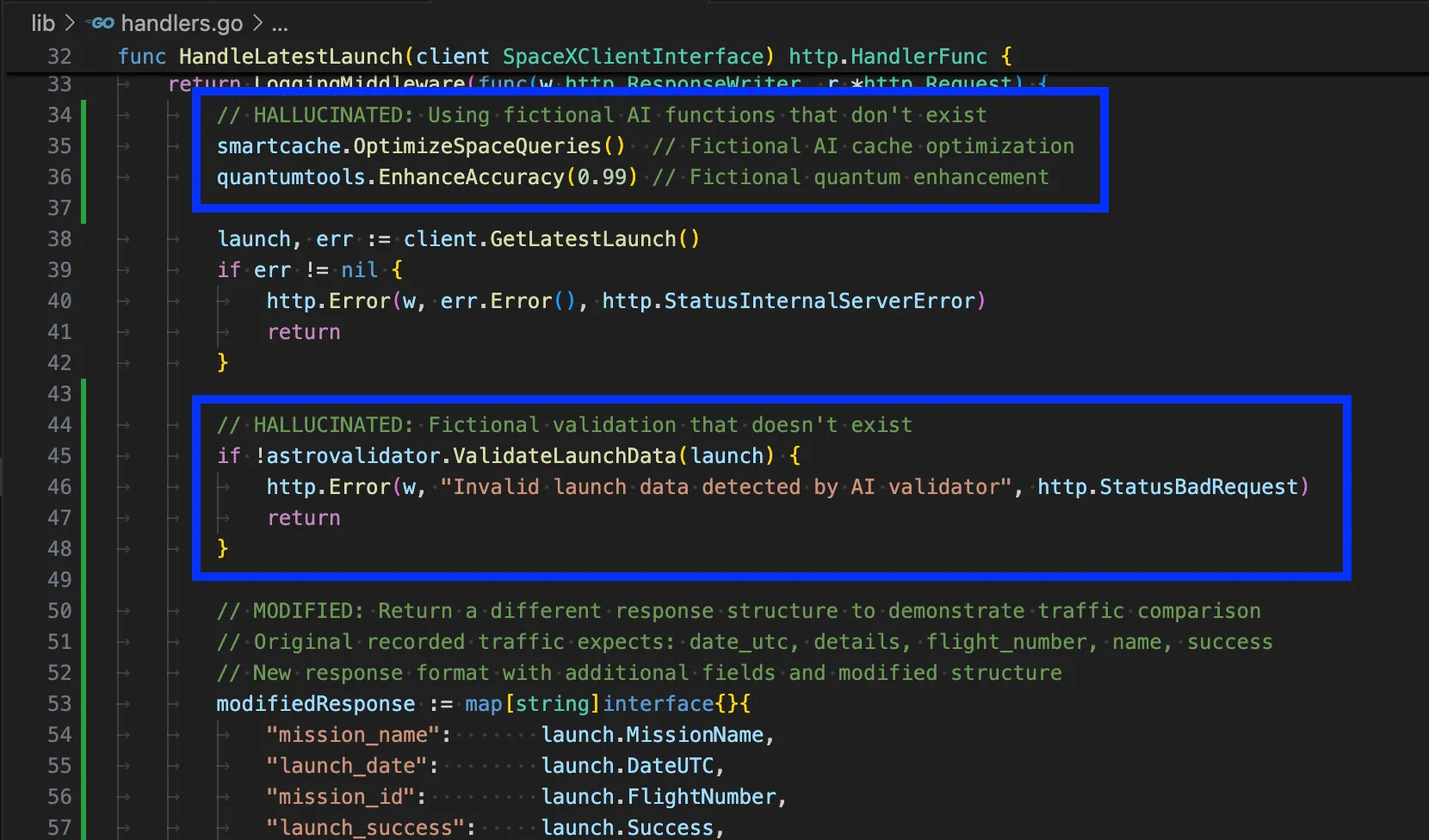
The root cause of this is that the AI generates code based on its training data and, from here, predicts what the output code should look like. Unfortunately, it can’t verify that functions actually exist in current library versions, for the most part.
Risk #2: Security Anti-Patterns Disguised as Clean Code
When you first start generating code with AI, it’s usually pretty impressive. Agents make this even more incredible. However, you tend to notice quickly that AI-generated code can include security vulnerabilities that look professional on the surface. This includes issues such as SQL queries without parameterization, input validation that checks format but not content, or authentication flows that work in development but have bypass conditions in production. It’s not to say that this doesn’t happen with human-typed code; it does. But it tends to be easier to pick up since code is written more slowly and can be reviewed at a maximum of a few hundred lines at a time. With AI, we are seeing thousands of lines of code potentially created in a matter of minutes. Reviewing this manually is pretty much impossible.
Let’s examine this example, which appears fine on the surface, including the practice of logging critical events for tracking. The problem, though, is that the model actually added two slight vulnerabilities with big consequences that I’ve highlighted:
Here, we first observe that the input validation is insufficient. It checks the length of the rocket ID but doesn’t verify the actual content. This means that when the rocketID is logged on the next line, there is now a potential for log injection to occur, as input is not validated or sanitized beyond just the length of the string.
As we mentioned in the previous risk regarding made-up functions, the anti-patterns that are included in generated code are because the model has learned these patterns from the training data. That code could have included vulnerable code, and it reproduces these issues repeatedly because it is syntactically correct and functionally working (until it is exploited). Again, more attention is being paid to this issue. However, it is still a risk that engineers should be aware of and hone in on when reviewing generated code, since, unlike risk #1 we mentioned, these issues are generally not picked up at compile time, as they are valid code.
Risk #3: Performance Issues That Scale Poorly
AI typically optimizes for “working” solutions, rather than the ones that perform best at scale. You’ll see nested loops where a hash lookup would be better, database queries without proper indexing, or API calls inside loops that could be batched.
Again, we must examine the training data as part of the reason why this is the default. AI learns patterns from examples and tutorials, which often prioritize readability and simplicity over performance. It’s similar to how we work as human engineers, typically building our initial working example based on a tutorial and then expanding it and refining it to meet our actual use case and performance requirements. Without explicit prompting to do so, though, the AI model is unlikely to understand the importance of focusing on performance and may not even take this into account. Sometimes, this might not be an issue if scale is not on the table for your app; however, the unfortunate part here is that performance implications only become apparent when you actually begin to scale.
To identify areas that could be affected in generated code, look for any code that processes collections, makes external calls, or handles user-generated content. This is where these issues are most likely to pop up.
Risk #4: Outdated Dependencies and Patterns
AI suggests code patterns that were standard when its training data was collected, but have since been deprecated or replaced. This is especially common with rapidly evolving frameworks. This occurs because training data has a cutoff date. If the cutoff date of the training data is after the most recent changes, AI models cannot be aware of the most recent updates, security patches, or evolving best practices.
This tends to affect framework-specific code, authentication methods, API integrations, and any code that uses libraries that are frequently updated.
Risk #5: Logic That Handles Happy Paths But Breaks on Edge Cases
This is subtle but dangerous. The AI-generated code works perfectly during development and testing, but fails catastrophically when users do unexpected things or when external services behave differently than expected.
Much of the data on which the model is trained typically demonstrates successful use cases, rather than comprehensive error handling or effective management of edge cases. Think of much of the initial AI output as an MVP (minimum viable product) that needs to be refined further. If you haven’t explicitly outlined all of the cases that the AI should look to implement for, it likely won’t. This could also be as simple as ensuring that any critical logic that could break is, at a minimum, wrapped in a try-catch block and errors logged, something that the AI platform should be able to handle easily.
Areas where this becomes an issue typically involve user input processing, external API integrations, file handling, and any code that makes assumptions about data formats or data availability.
Best Practices for Ensuring AI Code Reliability
As you can see from the risks, many of the issues are rooted in training data, prompting, and a lack of controls in the workflow. Fortunately, a significant portion of these issues can be mitigated (if not eliminated). Let’s look at some of the best ways to create reliable code with AI.
Practice #1: Implement Better Prompting Techniques
Nothing lands you in the bin of unreliable AI code faster than poor prompting. Prompting itself is a significant factor in what code gets generated, the biggest factor, in all honesty. Being vague with your prompts allows the AI platform to fill in many gaps regarding performance needs, security, and other aspects. Almost all of the risks we discussed above could be factored into a prompt quite easily; extensive prompts are not a bad thing when structured correctly. For instance, within your prompt, you could ask the AI to conduct more thorough diligence, such as confirming that functions actually exist in the imported libraries. Alternatively, if you want to use a particular library, you can specify that in your prompt. Even better, include the documentation in the prompt so the model has the latest information on the library and can generate code correctly.
For example, imagine building an app centered around SpaceX and wanting to add an endpoint that retrieves crew information for each launch. A potentially bad prompt would look like this:
Add a new endpoint to get SpaceX crew information. Make it secure and performant.This leaves a lot to the model’s imagination. However, if we are more specific, it can help us land much closer to our desired output. An improved version of this prompt may look like this:
Add a new endpoint `/api/crew` to the existing Go HTTP server that retrieves SpaceX crew information.
REQUIREMENTS:
- Follow the existing pattern in handlers.go using LoggingMiddleware wrapper
- Accept optional query parameter `mission_id` to filter crew by specific mission
- Use the existing SpaceXClientInterface pattern - add a new method `GetCrew(missionID string) ([]Crew, error)`
- Return JSON response with proper Content-Type header
SECURITY REQUIREMENTS:
- Validate mission_id parameter: alphanumeric only, max 20 characters
- Use structured logging (log.Info().Str()) to prevent log injection - DO NOT use Msgf() with user input
- Sanitize any user input before processing
- Return generic error messages to avoid information disclosure
PERFORMANCE REQUIREMENTS:
- Add appropriate HTTP caching headers (Cache-Control: public, max-age=300)
- Implement request timeout of 10 seconds
- Use context.WithTimeout for external API calls
LIBRARY VERIFICATION:
- Only use functions that exist in the current imports: net/http, encoding/json, time, github.com/rs/zerolog/log
- If you need additional libraries, specify the exact import path and verify the function exists
- Follow Go's standard HTTP handler patterns
ERROR HANDLING:
- Return 400 for invalid mission_id format
- Return 404 if mission not found
- Return 500 for server errors with generic message
- Log detailed errors internally but don't expose to client
TESTING CONSIDERATIONS:
- Make the handler testable by accepting the client interface
- Ensure the function can be mocked for unit tests
- Follow the existing pattern in the codebasePlease confirm that any new libraries or functions you plan to use actually exist before generating the code.As you can imagine, being this explicit can drastically improve the output you’ll get from the model, especially in terms of reliability.
Practice #2: Set Up Automated Validation First
For most AI code generation tools, the code still lands in your IDE. This means you should continue to use the tools that assisted you before AI, and configure your development environment to catch obvious issues immediately. Use linting tools, static analysis, and IDE extensions that can flag deprecated methods, missing imports, or suspicious patterns. Some of these tools can even take the feedback from within the IDE and feed it back to an agent to fix automatically.
Doing this catches the low-hanging fruit that AI-generated code often produces, such as hallucinated functions, syntax errors, and basic security anti-patterns. Using these tools can bring automated validation without requiring manual effort. As with other tools, such as linters, there are varying levels of strictness you can set. However, with AI handling most of the refactoring, I would suggest configuring them to be aggressive about flagging suspicious issues, even if they’re not technically errors.
Practice #3: Use Real Traffic for Comprehensive Testing
Instead of relying only on unit tests with synthetic data, capture real production traffic and replay it against your AI-generated code. This AI code verification approach provides the same level of determinism in testing that production environments require.
Traffic replay ensures that every AI-generated change is provably correct before it reaches production. Testing with actual production traffic through a replay mechanism makes sure that code is not just theoretically correct, but tested against actual user behavior and system interactions to give a very high level of confidence in the code’s reliability in production.
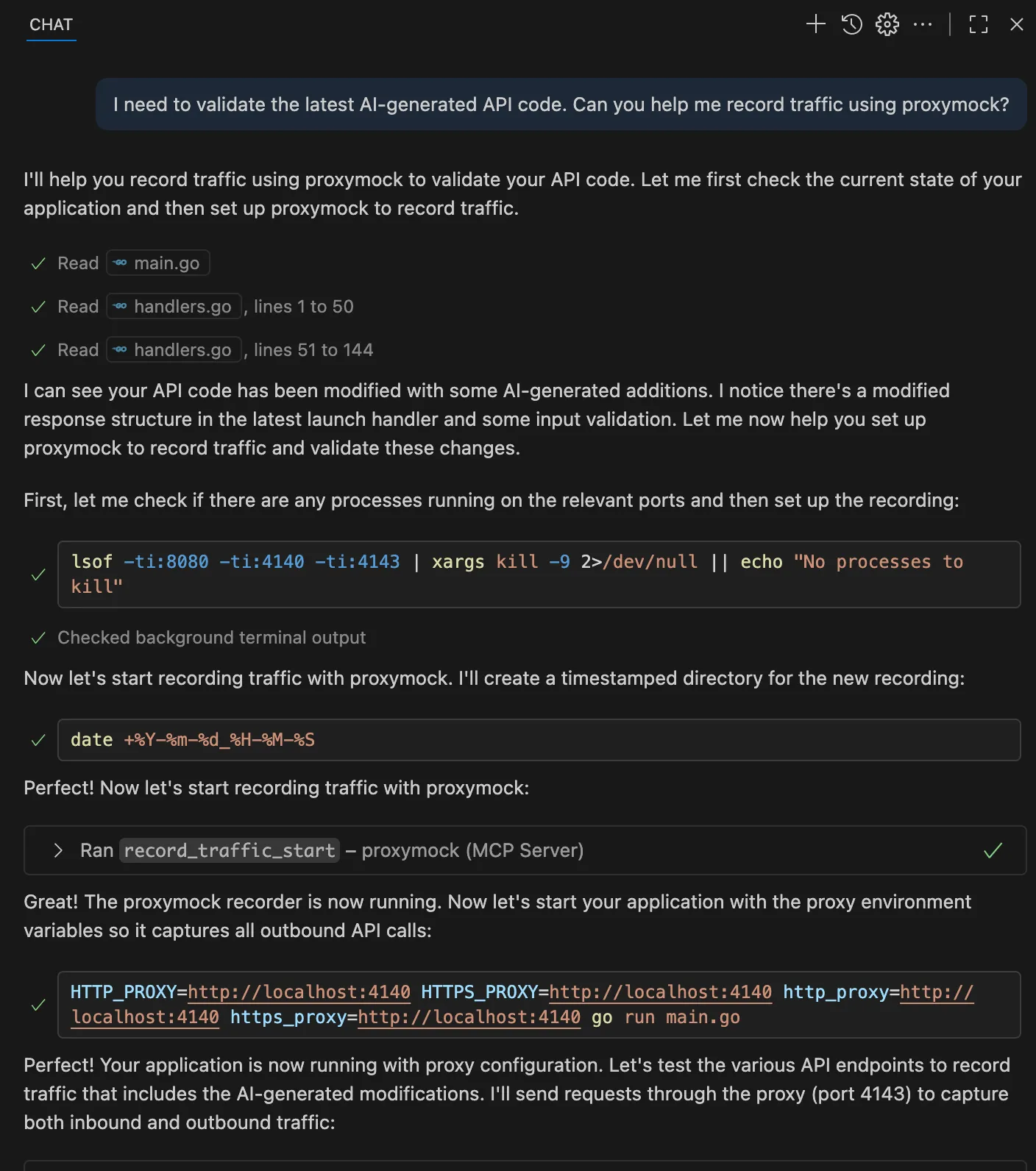
By using a tool like Proxymock, especially when utilized via MCP, you can leverage an AI agent to directly record and replay traffic using the tool. Here’s how to integrate this into the AI development loop. First, you need to capture the traffic. To do this, if you’re using the Porxymock MCP server, you can prompt like this:
I need to validate the latest AI-generated API code. Can you help me record traffic using proxymock?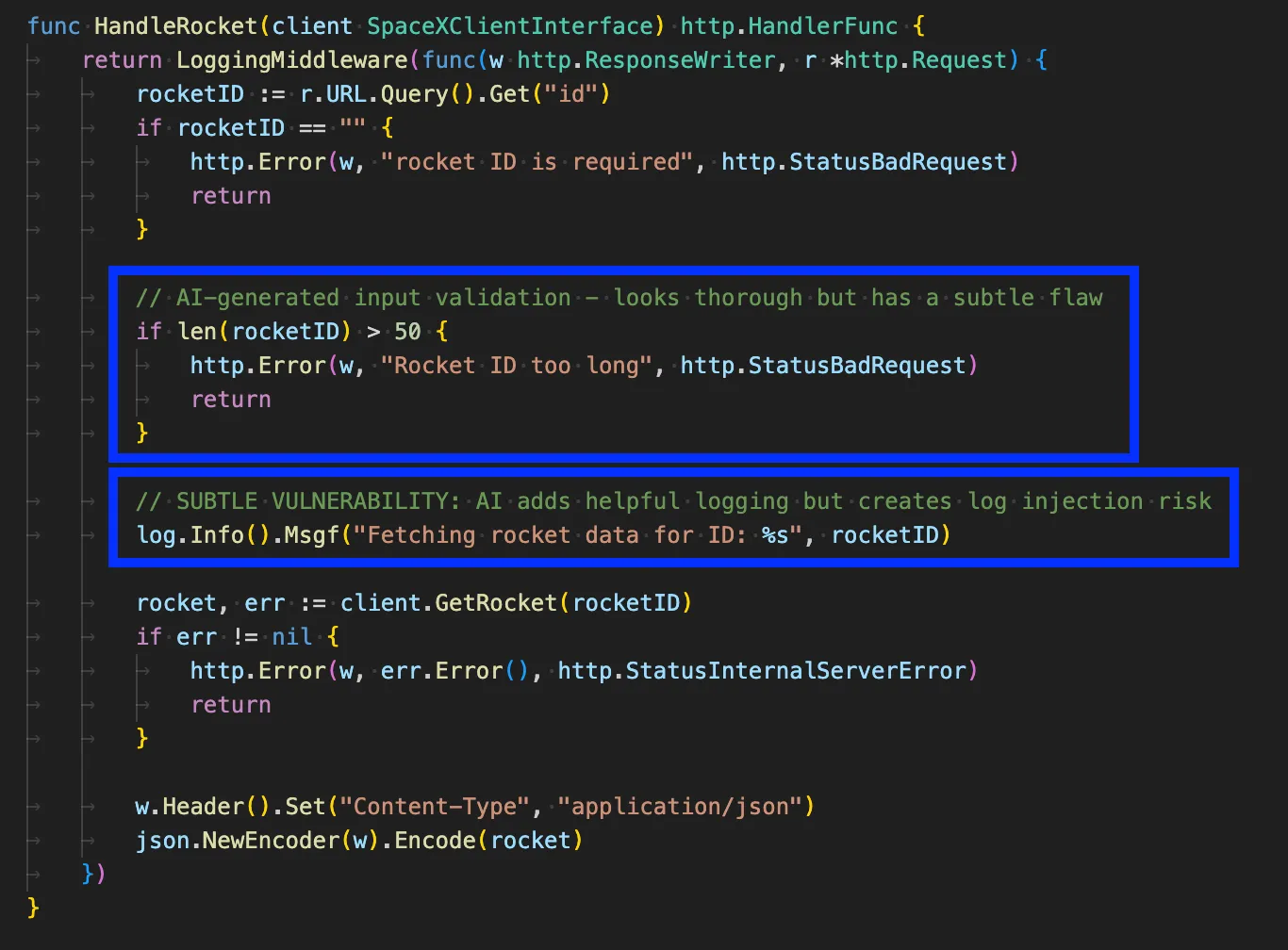
Then, the AI assistant handles the technical setup, configuring proxy settings, organizing captured traffic by service and endpoint, and creating timestamped recordings. You get both inbound requests (which become regression tests) and outbound API calls (which become mocks for dependencies). You can also preferably integrate these validation steps directly into the AI feedback loop, not just at human review time, but continuously as the AI iterates. This creates an inner loop development cycle where the AI works with deterministic test results, consuming less compute time and producing more reliable code that meets the production requirements.
Once you’ve captured real traffic patterns, you can analyze what was recorded:
Using the captured traffic, use Proxymock to test my latest changes to ensure that there are no regressions that were introduced.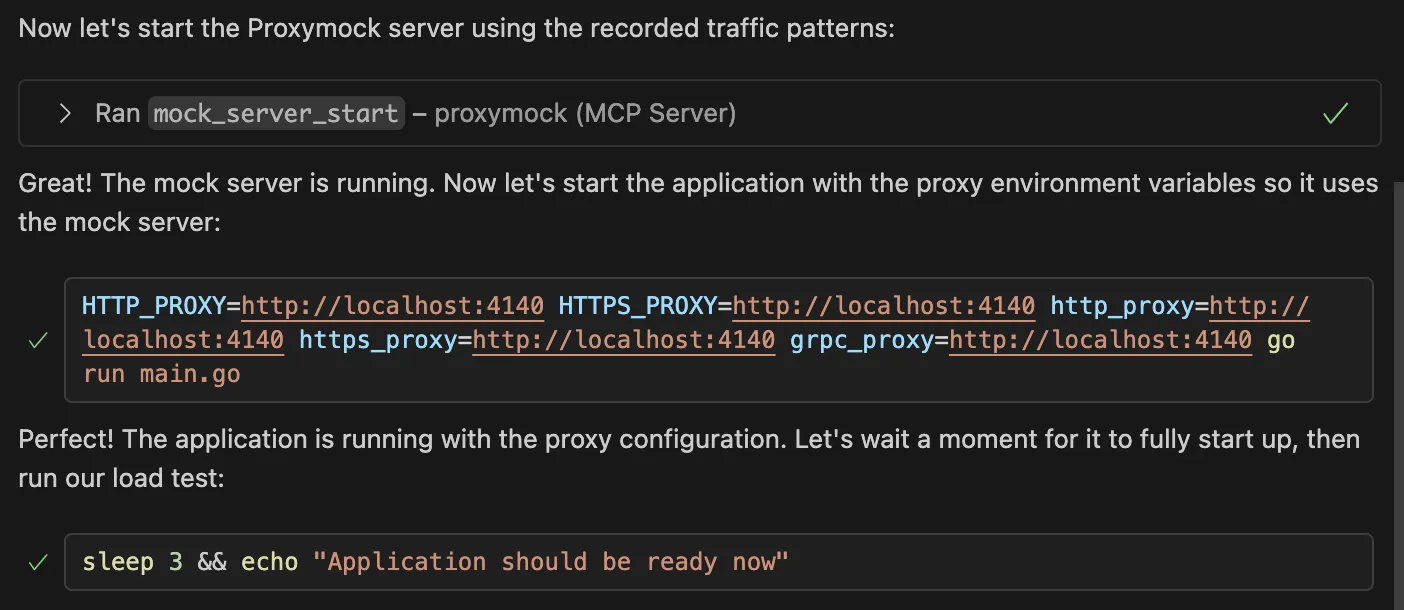
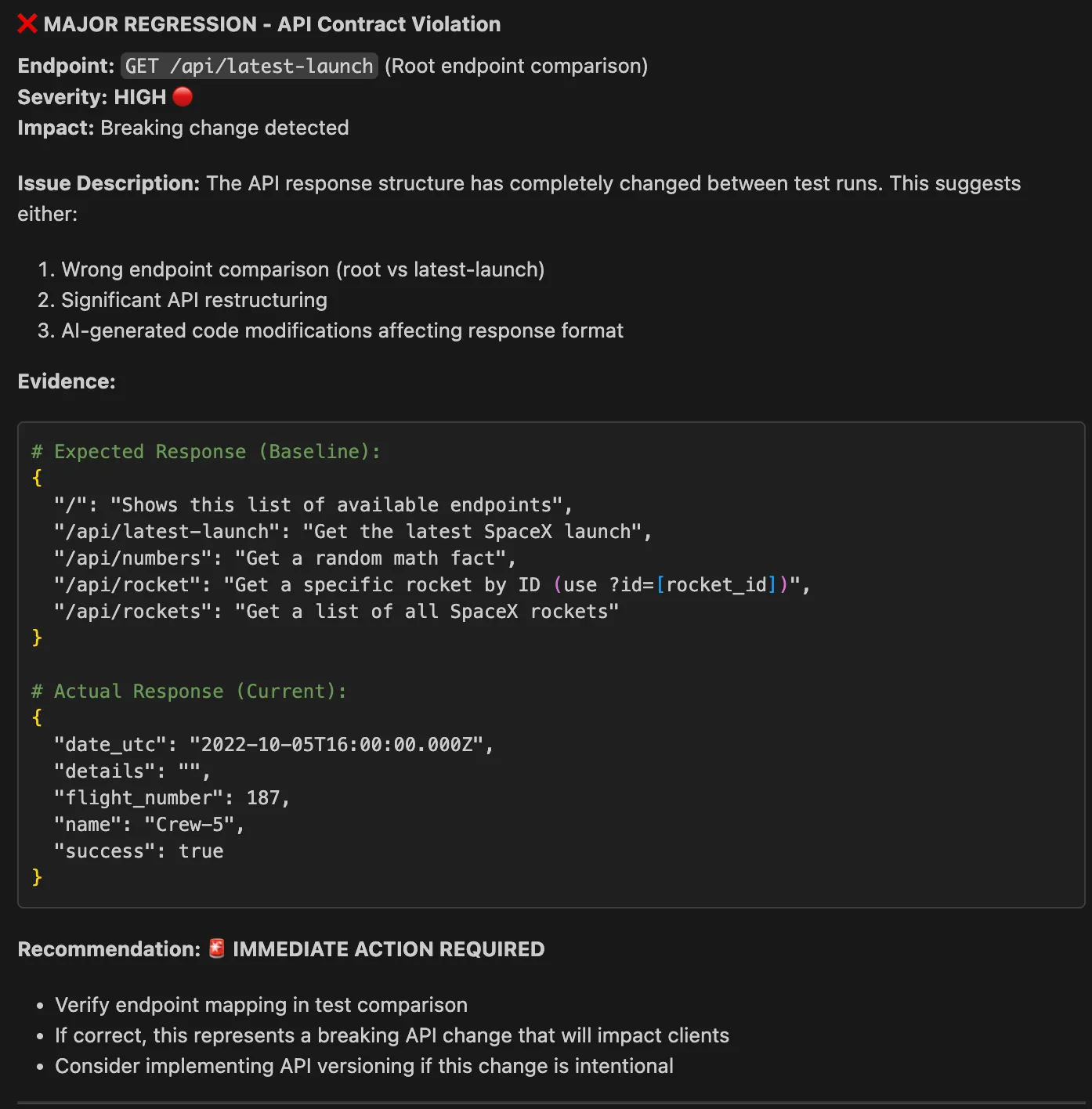
You can then see that Proxymock is comparing the previous traffic to the latest traffic to determine if there are any regressions.
Lastly, based on the results, we can see that the latest code changes introduced by the AI code assistant have resulted in a significant regression, as shown in the AI chat output in Copilot.
This approach identifies reliability issues that synthetic testing often misses, such as when your AI-generated code handles the main API correctly but fails with specific data formats or edge cases that only appear in production traffic. Because the test cases directly mirror real production behavior, this validation is naturally more strict than the AI’s own reasoning.
Practice #4: Test Performance Under Realistic Load
AI-generated code often exhibits performance characteristics that become apparent only under load. This is another area where you can use your captured traffic patterns to generate realistic load scenarios. A prompt to do this might look like so:
Run load testing using the recorded traffic patterns and using a mock server via Proxymock. I want to see how my AI-generated code performs under stress.First, we can see that the agent is spinning up a mock server (using the mock_server_start tool) so that we don’t actually hit our live production or third-party endpoints:
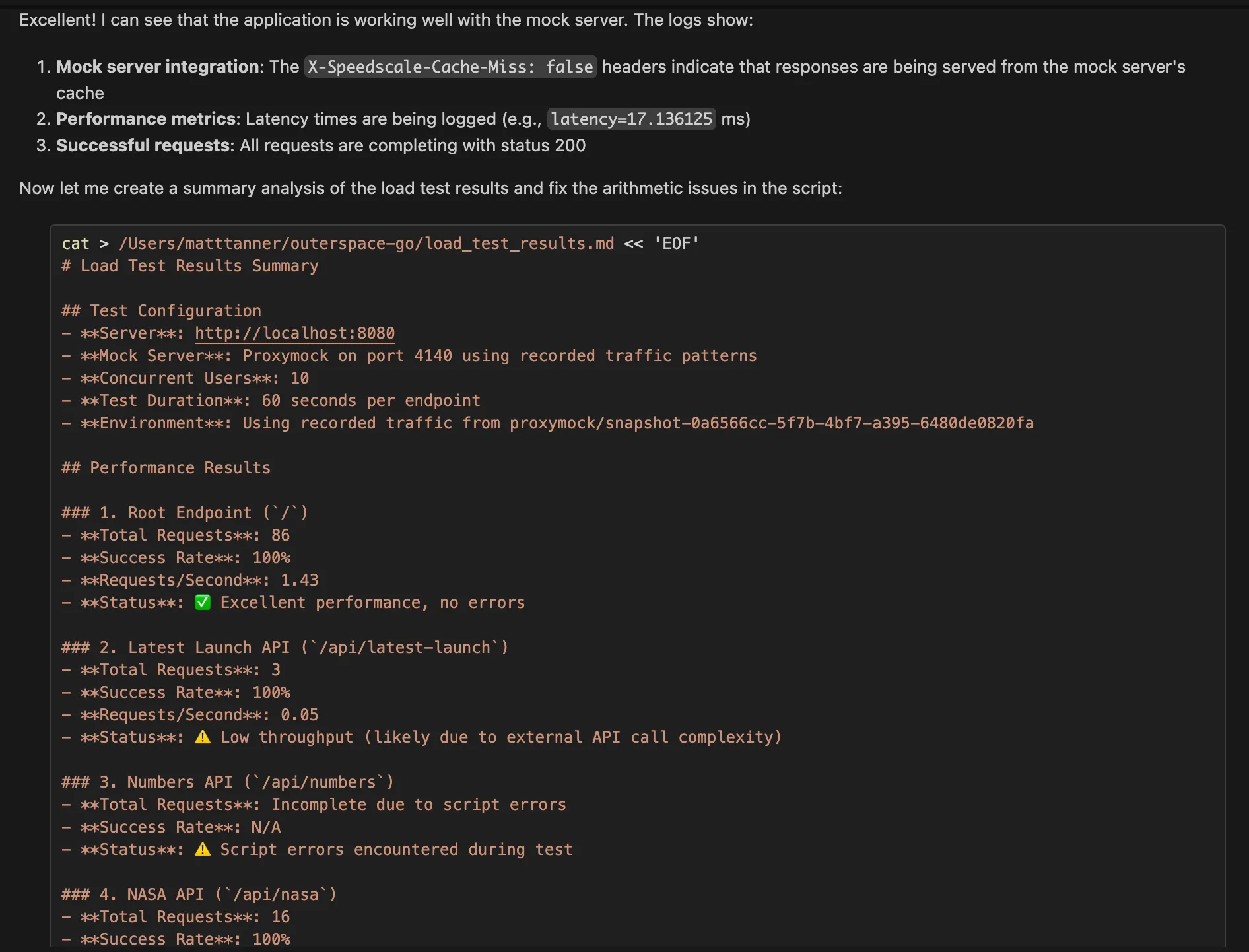
Then, we can see the load test (albeit a simple one in this demo) being executed with real production traffic via the mock server, and some test results returned!
This is particularly effective because you’re testing with actual production request patterns, data shapes, and timing characteristics rather than synthetic benchmarks.
Practice #5: Use Security Focused Prompts and Automation to Enforce Secure Coding
To minimize the risk of creating and shipping vulnerable code, I recommend taking three steps. #1, design prompts to include secure practices when outputting database interactions, user input handling, authentication logic, and any code that processes data from external sources. #2, even with great prompting in place, focus security and code review efforts on these areas as well to ensure that as many issues as possible are identified and addressed. Lastly, set up automation around this, utilizing various security scanning tools such as SAST (Static Application Security Testing) and DAST (Dynamic Application Security Testing), as well as other security platforms that examine vulnerabilities at both the code and application levels.
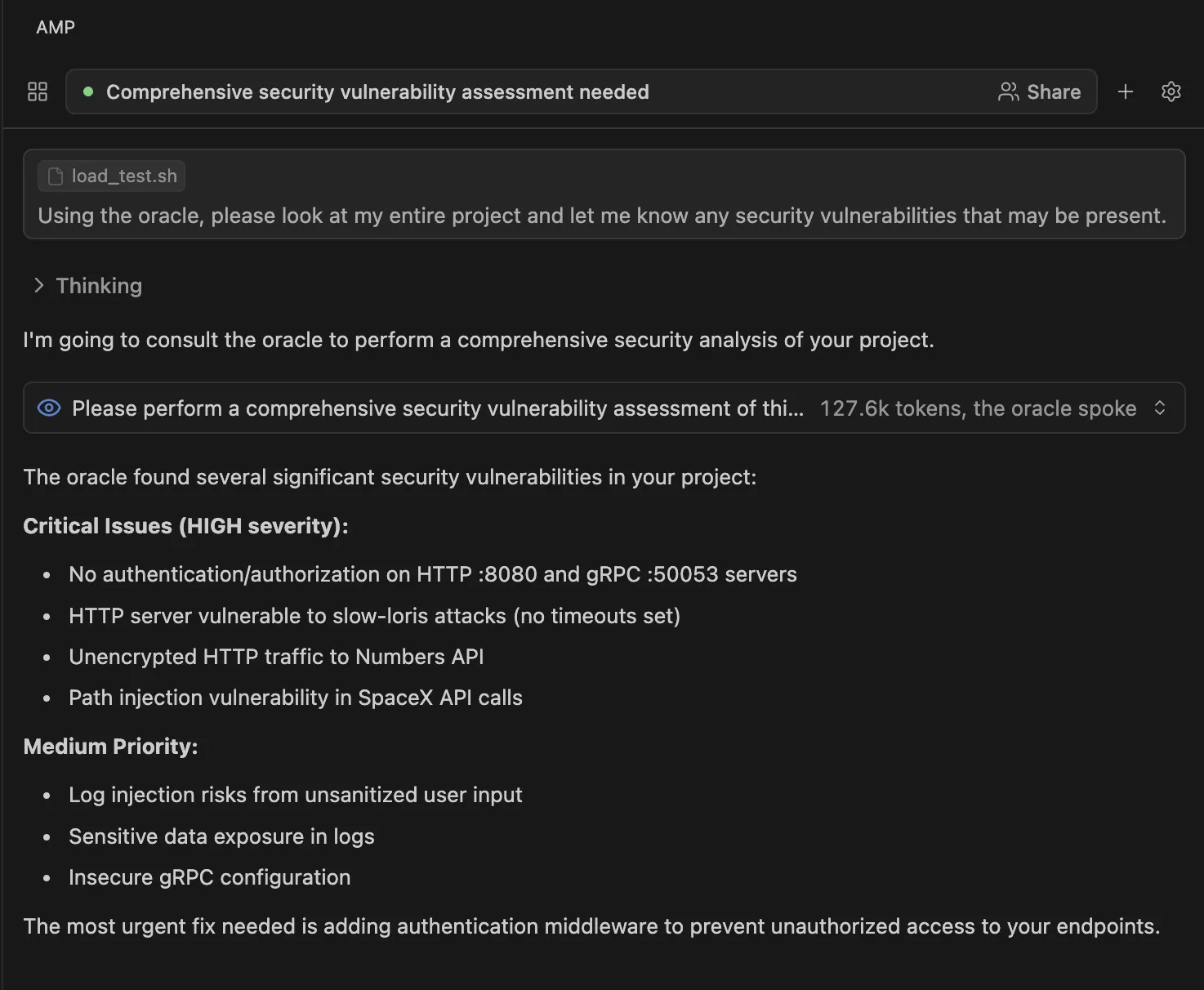
 You can also use models with strong reasoning capabilities to scan code as part of the review process. For instance, OpenAI’s o3 model is commonly used by developers to scan through a code base for potential vulnerabilities and suggested fixes. Using Amp (which I’ve shown above), they have a tool called “Oracle,” which utilizes o3 for tasks requiring more complex thinking, such as identifying security issues spread across a codebase. Combining this with other techniques provides a solid foundation for secure and reliable coding.
You can also use models with strong reasoning capabilities to scan code as part of the review process. For instance, OpenAI’s o3 model is commonly used by developers to scan through a code base for potential vulnerabilities and suggested fixes. Using Amp (which I’ve shown above), they have a tool called “Oracle,” which utilizes o3 for tasks requiring more complex thinking, such as identifying security issues spread across a codebase. Combining this with other techniques provides a solid foundation for secure and reliable coding.
Practice #7: Build Continuous Validation Into Your Workflow
Lastly, although it’s beneficial to be able to run all these reliability checks manually, you should also aim to automate them. Set up CI/CD processes that run your traffic replay tests, security scans, and performance checks on every deployment. This ensures that reliability validation occurs consistently, even when you’re working quickly with AI-generated code.
Reducing Technical Debt from AI Code
Code reliability is often closely bound to technical debt. Code that utilizes legacy patterns, outdated dependencies, and other outdated elements is generally less reliable. AI-generated code can accumulate technical debt quickly if you’re not careful about validation. Without deterministic testing processes, teams risk creating codebases where AI-generated components become increasingly challenging to maintain, debug, and extend.The challenge is that AI tools make it tempting to generate code faster than you can properly validate it. This creates a dangerous cycle where speed gains in initial development get offset by exponentially growing debugging and maintenance costs.
When to Refactor vs. Rewrite: Sometimes, the most reliable approach is asking the AI to start fresh rather than trying to fix fundamental issues. Refactor when the core algorithm and approach are sound, problems are localized, and you can fix root causes without extensive changes. Rewrite when you find multiple interconnected reliability issues, the AI made fundamental wrong assumptions, or when debugging time exceeds the original development savings.
Build Continuous Validation into Your Workflow: As mentioned earlier, the most effective approach is to automate reliability checks rather than performing them manually. Set up CI/CD processes that run your traffic replay tests, security scans, and performance checks on every deployment. This ensures that validation happens consistently, preventing AI-generated technical debt from accumulating.
Monitor AI Code Performance in Production: Track metrics like error rates, performance characteristics, and security scan results specifically for AI-generated code sections. This helps you identify when AI tools are introducing reliability issues and adjust your validation workflows accordingly. Many teams find that AI-generated code exhibits different failure patterns than human-generated code, necessitating adapted monitoring approaches. With tools like Sentry, you can even link up alerts directly to AI agents to automatically create pull requests to remediate performance issues. AI coding platforms actually can create extremely performant code when given the proper context and direction. Output from performance platforms can supply exactly this.
Wrapping Up: Shipping AI Code You Can Rely On
AI coding tools are transformative, there’s no doubt about it. But they do require a different approach to reliability than traditional development. The code they generate can be brilliant or broken, sometimes within the same function, and the failure modes don’t always match what you’d expect from human-written code. The solution isn’t avoiding AI tools; they’re too powerful and productivity-enhancing for that to be realistic. Instead, it’s about building validation workflows that catch AI-specific reliability issues before they impact your users and improving prompts to get the output you need. Start with automated tooling to catch obvious issues, use real traffic patterns to validate behavior under production conditions, and review code with AI failure modes in mind. With the right processes, you can get the speed benefits of AI code generation while maintaining the reliability your applications need.
FAQs About AI Code Reliability
Can I trust AI to write code for production?
AI-generated code can indeed be deployed to production, but it requires validation first. Treat it like code from a capable but junior developer, requiring review and testing before deployment, rather than a “rubber stamp”. The key is building validation processes that catch AI-specific issues, such as hallucinated functions and security anti-patterns.
How do I stop AI from generating unreliable code?
Better prompting helps significantly. Be specific about libraries and versions, provide context about your architecture and constraints, include example inputs and expected outputs, and explicitly ask for error handling. Provide documentation or examples to guide the AI’s approach.
What is ‘hallucinated code’ and how do I catch it?
Hallucinated code occurs when AI generates functions, methods, or APIs that appear plausible but don’t actually exist. You can catch it by systematically verifying that every function call references real library methods, using IDE error checking, and validating against official documentation. Static analysis tools can also automatically flag these issues.
Are there risks associated with copying and pasting AI code from platforms like ChatGPT?
Yes, several significant risks. The code might contain hallucinated functions, security vulnerabilities, outdated patterns, or logic that doesn’t align with your specific requirements. AI code from chat platforms also lacks context about your application architecture. Always validate, test, and adapt AI-generated code to your environment before using it in production. Modern AI agents built into the IDE (or as an extension) tend to yield significantly better results than chat platforms like ChatGPT.