At Speedscale, we are on the cutting edge of defining autonomous testing for the cloud era. However, we aren’t the only company trying to solve this problem and we enjoy learning from every perspective. That’s why Facebook’s recent blog article about autonomous testing caught my eye. They’ve built a sophisticated autonomous test system that introduces many of the same techniques we utilize. Their article isn’t overly long and is definitely worth the read if you’re trying to debug your code before it hits production. By way of encouragement, I’ll refrain from trying to summarize it in a few sentences. Instead, let’s talk about some of the key insights in Facebook’s blog and how it can help you improve your own testing systems.
Existing approaches to testing just don’t work for cloud native
We’re in the era of building smaller connected services vs. pure monoliths. If you know your CS history, you hear the echo of Conway’s law: “the structure of the team tends to be reflected in the structure of the technology” (heavily paraphrased). In other words, it was only a matter of time before the small agile team started creating the small container. The upside is that development speeds up because ownership is clear and every team can express their own preferences within their domain. I like Go while you like node.js, no problem. Unfortunately, many cloud native companies are starting to realize that this change has downstream reliability consequences. In particular, multivariate problems spanning services appear to be rising. This is one of the reasons why we see increasing popularity for cross-process diagnostics like tracing and Open Telemetry.
**“**Unit tests are useful for checking the logic within a service but fail to test the dependencies between services.”
Less discussed is that once you’ve got unit tests, most other legacy testing methodologies are near useless for cloud native apps. Maintaining a realistic integration environment with correct data, dependencies and infrastructure is almost harder than keeping production running. Most organizations attempt to bail out the boat by increasing production monitoring, creating ever more brittle CI pipelines or using canaries and feature flags. Infrastructure as code and GitOps also help but the problem of realistic data and writing tests and mocks remain. The automation just hasn’t caught up to the problem yet.
Mocking should be based on real recorded behavior, not custom coding
“The mocks inherently implement only some of the behaviors from the real dependencies. As a result, some bugs can go undetected. Maintaining the mocks also requires a considerable engineering effort.”
My firsthand experience tells me that mocks are hard to write, hard to reason about and almost immediately out of date. Turns out I’m not alone in that observation. You’ll hear infrastructure engineers talk about “pets vs cattle” and I think the metaphor applies equally to mocking. Writing effective mocks requires love, caring and deep behavioral insight, like owning a pet. Unfortunately, that kind of care and feeding just isn’t part of the cloud native philosophy.
To align mocking with the rest of system, you need to manage a herd of constantly changing tests as a group instead of curating a tiny set of happy paths. At Speedscale we record real API calls from earlier versions of the application and then use them to generate new mocks and incoming load. If a mock created yesterday falls out of date, just delete it and create a new one from what’s going on today. Make it part of your CI pipeline as an automatically updating harness and then forget about it. This works pretty well for a wide range of use cases.
Rigid assertions create noisy tests that eventually get turned off
“Most test oracles are custom assertions about the service’s behavior. While these are similar in principle to unit test assertions, they are only able to inspect the externally visible behavior of the service under test, not its internal state.”
Firstly, I love the name test oracles. I wish I had thought of it. For an autonomous cloud testing system to function you have to check the outputs in some kind of automated way. Facebook combines recordings and custom assertions and that’s essentially how we do it as well. You can save yourself a whole lot of custom instrumentation and logging by simply comparing the JSON schema or data vs what was observed previously.
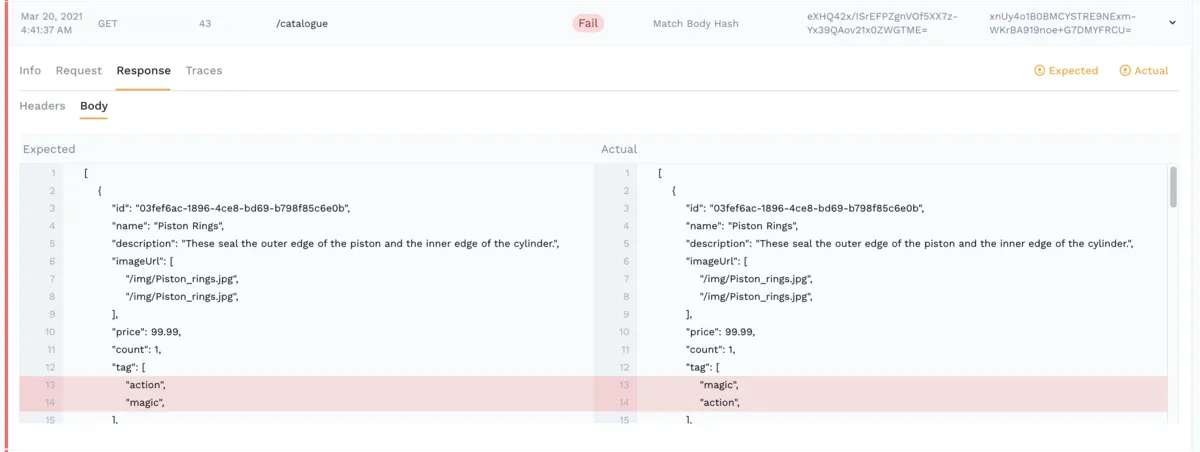 The biggest challenge we’ve seen is making sure that these “oracles” are permissive enough to not generate noisy false positives. Facebook doesn’t detail exactly how they accomplish this but our users generally save rigid value checks for important items like status results and stick with checking higher level abstractions like API contracts or aggregates for most behaviors.
The biggest challenge we’ve seen is making sure that these “oracles” are permissive enough to not generate noisy false positives. Facebook doesn’t detail exactly how they accomplish this but our users generally save rigid value checks for important items like status results and stick with checking higher level abstractions like API contracts or aggregates for most behaviors.
Reliable automated testing requires proper isolation
“Isolation is a particularly important element in autonomous testing. This is because the testing infrastructure decides which inputs to use. … We periodically record a small fraction of requests that hit production services, sanitize them, and make them available to the testing infrastructure”
It’s almost impossible to take an automated testing approach if both the incoming requests and the downstream mocks are hand written. Facebook has a very nuanced solution to this problem. They selectively route individual transactions based on intent. They don’t seem to just route to a prod vs non-prod backend API, they route the GET calls differently than the PUT calls in the same API. Frankly, I’m impressed. This approach requires a deep understanding of the application behavior that usually comes from the developer themselves. Facebook appears to have the discipline and bandwidth to do this effectively.
Most of our users take a slightly different approach to cloud testing - dynamically provisioned environments. Speedscale recreates similar ephemeral environments as part of our Kubernetes operator. For instance, let’s say your service relies on a Postgres database and an S3 bucket. Speedscale will observe those data stores in the real system and automatically replicate the communication in test. It’s fully automated and works for many use cases. However, there are many ways to approach this including OSS, DIY and commercial tools. Generally these approaches allow a high degrees of customization and tweaking. Here are some examples:
https://github.com/garden-io/garden
https://engineering.dollarshaveclub.com/qa-environments-on-demand-with-kubernetes-5a571b4e273c
Good luck!
There’s a lot to digest in Facebook’s autonomous testing post but these are some off the cuff observations. Cloud native testing is a rapidly evolving space with many competing ideas. Whenever I’m digesting these ideas I always ask, “Does this increase our automation without increasing noisy false positives?” Every time we compromise on this ideal, we pay the price when we hit our next scale milestone. Hopefully this helps you avoid some pitfalls on your journey.