








Full payload capture
Record complete request and response bodies, headers, auth, and timing from Kubernetes, ECS, desktop, or agent traffic. Not sampled. Not truncated. Everything your API testing needs.
Validate AI-generated code with real production traffic before merge.
AI agents introduce bugs faster than your team can triage them. Speedscale captures the exact production request that broke, replays it in a sandbox, and hands your AI agent the real data to fix it.
No credit card required • 5-minute setup • 30-day free trial
FLYR, Sephora, IHG, and platform teams worldwide use Speedscale to capture real production payloads and replay them against AI-authored changes.









The reproduction gap
A failure appears in production. You can't reproduce it in staging. Your APM shows a trace but not the payload. The AI agent you ask to fix it has never seen what your system actually looks like under real load. Speedscale was built for exactly this, across your entire Kubernetes and API testing pipeline.
See exactly what each approach gives you when a production failure needs to be understood, reproduced, and fixed.
| Capability | Legacy APM | Static analysis | Speedscale |
|---|---|---|---|
| Captures the full request payload | Sampled traces. No request bodies. | No runtime data at all. | Complete payloads: headers, bodies, auth, every call. |
| Deterministic reproduction of failures | Fires an alert. No replay capability. | No runtime behavior. | Replay any production snapshot on demand. |
| Gives AI agents real data to fix bugs | Dashboard only. No coding context. | Diffs only. No production signal. | MCP-native context for Claude Code, Cursor, and Codex. |
| Catches behavioral regressions before merge | Detects after deploy. Customers see it first. | Syntax and types only. | Replays real traffic against every AI change before merge. |
Headers, body, auth tokens, query params. The full payload, not a sampled trace that lost the body somewhere in transit.
Replay it in a disposable sandbox against your change. No live dependencies, no flakiness, no guessing.
Your AI coding agent gets the actual request and response that triggered the failure, so it can fix the real problem instead of guessing at it.
Every pull request gets a before/after payload diff so reviewers can verify the fix is complete.
Capture the payloads. Replay the failure. Ship the fix with proof.
Full payload visibility and deterministic replay for the age of AI-generated code.
Record complete request and response bodies, headers, auth, and timing from Kubernetes, ECS, desktop, or agent traffic. Not sampled. Not truncated. Everything your API testing needs.
Replay the exact production scenario in a disposable sandbox. Same payloads, same headers, same upstream responses. Every time, without flakiness.
Claude Code, Cursor, and Copilot can't fix what they can't see. Give them the actual request and response that triggered the failure, not a stack trace.
Sensitive fields are masked automatically. Payload structure stays intact, so you get accurate reproduction without compliance risk.
Serve production traffic snapshots through MCP so AI coding agents can pull the exact request that failed and replay it without touching production.
Every pull request gets a before/after payload diff. Reviewers see exactly what changed and whether the fix actually addresses the root cause.
Capture production traffic, replay it in your Kubernetes CI pipeline, and give your AI coding agent the context it needs through MCP.
Validate AI-generated code with real production traffic before merge.
You feel faster, but you're spending hours reviewing code you didn't write and debugging failures you can't reproduce. Speedscale replays real production traffic against every AI change so you ship with proof, not hope.
No credit card required • 5-minute setup • 30-day free trial
FLYR, Sephora, IHG, and platform teams worldwide use Speedscale to validate AI-generated changes against real production behavior before merging.
The velocity trap
AI promised to make you faster. Instead, you're spending more time reviewing code you didn't write, chasing bugs that only appear in production, and rewriting changes that passed every check but still broke. The teams actually moving fast are the ones who test every AI change against real traffic before it merges. Speedscale plugs into your Kubernetes and API testing pipeline to make that automatic.
See where the velocity tax actually comes from, and where Speedscale cuts it.
| Capability | Legacy APM | Static analysis | Speedscale |
|---|---|---|---|
| Catches behavioral regressions from AI code | After deploy. Customers see the failure first. | Syntax only. Misses all runtime failures. | Before merge. Replays real production traffic in CI. |
| Shortens the defect feedback loop | Hours to days: alert, triage, reproduce, fix. | Seconds, but misses most AI-introduced bugs. | Seconds. Full payload replay catches what static tools miss. |
| Scales with AI-generated PR volume | Dashboards don't review code. | Overwhelmed by AI change set size and complexity. | Automated replay covers every change on every branch. |
| Gives AI agents context to self-correct | No integration with coding workflows. | No production signal. | MCP-native context for Claude Code, Cursor, and Codex. |
Record traffic once from Kubernetes, ECS, desktop, or agent surfaces. Replay it against every branch, every change, automatically.
Find the exact request an AI-generated change broke before it reaches staging or your customers.
Your AI coding agent gets the actual production request that exercises the change. Not a static schema. Not a synthetic stub.
Every pull request gets before/after behavioral diffs so reviewers ship with data, not hope.
Drop Speedscale into your CI pipeline and MCP workflow. Replay real traffic against every AI change before it reaches your customers.
Validate AI-generated code against real production traffic. Ship faster and catch failures faster.
Replay tens of thousands of real requests against every AI-authored change, automatically in CI. Regressions get caught before they compound into incidents.
Record complete request and response payloads from Kubernetes, ECS, desktop, or agent traffic. Share deterministic snapshots across branches without rebuilding environments.
Your AI coding agent can pull the exact production requests it needs through MCP to validate its own changes, without touching live systems.
Sensitive fields are masked automatically while payload structure stays intact. Full fidelity replay without compliance or governance risk.
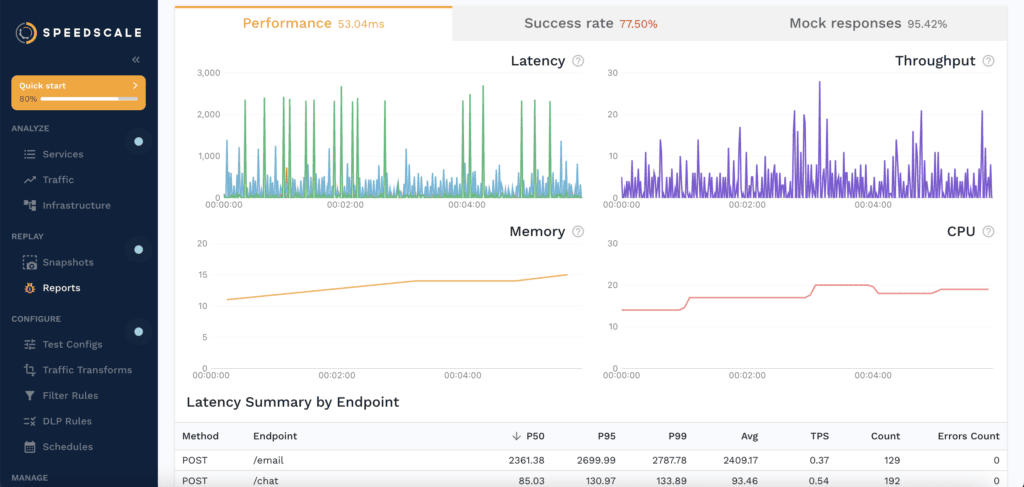
See exactly where an AI-generated change breaks: latency, payloads, auth, downstream contracts. All visible before it reaches your SLA or your customers.
Every AI-authored pull request gets before/after payload comparisons, latency diffs, and severity scores. Reviewers ship with data, not optimism.
Production traffic replay and behavioral diffs, built into your Kubernetes pipeline.