








Deep capture and inspection
Capture Traffic Context from production workloads and inspect failures at payload-level detail.
Validate AI-generated code with real production traffic before merge.
Speedscale turns observability data into action: deep capture, portable traffic context, AI-assisted debugging, deterministic reproduction, and fix validation before merge.
No credit card required • 5-minute setup • 30-day free trial
FLYR, Sephora, IHG, and platform teams worldwide use Speedscale to validate AI-generated changes against real production behavior before merging.









Observability that ships
This challenger focuses on five core observability capabilities: deep capture and inspection, data portability, AI integration, deterministic reproduction, and fix validation.
Compare monitoring-only workflows with replay-driven validation workflows.
| Capability | Legacy APM | Static analysis | Speedscale |
|---|---|---|---|
| Catches behavioral regressions from AI code | After deploy. Customers see the failure first. | Syntax only. Misses all runtime failures. | Before merge. Replays real production traffic in CI. |
| Shortens the defect feedback loop | Hours to days: alert, triage, reproduce, fix. | Seconds, but misses most AI-introduced bugs. | Fast feedback. Full payload replay catches what static tools miss. |
| Scales with AI-generated PR volume | Dashboards don't review code. | Overwhelmed by AI change set size and complexity. | Automated replay can run on each change in your configured branches. |
| Gives AI agents context to self-correct | No integration with coding workflows. | No production signal. | MCP-native context for Claude Code, Cursor, and Codex. |
Record traffic once from Kubernetes, ECS, desktop, or agent surfaces. Replay it against every branch, every change, automatically.
Find the exact request an AI-generated change broke before it reaches staging or your customers.
Your AI coding agent gets the actual production request that exercises the change. Not a static schema. Not a synthetic stub.
Every pull request gets before/after behavioral diffs so reviewers ship with data, not hope.
Validate AI-generated code against real production traffic. Ship faster and catch failures faster.
Capture Traffic Context from production workloads and inspect failures at payload-level detail.
Move captured traffic between environments, CI pipelines, and teams so observability data can be reused instead of recreated.
Expose Traffic Context to Claude Code, Cursor, and Codex so agents can debug with real production data.
Replay the exact failing production conversation in a controlled sandbox to reproduce bugs deterministically.
Run before/after comparisons on replayed traffic and confirm that each fix resolves the real regression before merge.
AI-authored pull requests can include before/after payload comparisons, latency diffs, and severity scores. Reviewers ship with evidence, not optimism.
Production traffic replay and behavioral diffs, built into your Kubernetes pipeline.
Your service already produces the best test data you will ever have. Capture it, run without your dependencies, and see exactly what your change broke.
brew install speedscale/tap/proxymock
Also available via curl, and for Java, .NET, Node.js, Go, and Python.
proxymock record --app-port 8080capturing on :8080 -> 4919 requests
POST /api/checkout 1204
GET /api/cart/{id} 892
postgres://orders 2823
written to ./proxymock/recordedproxymock mock --in-dir ./proxymock/recordedmock server listening on :4143
postgres://orders matched
https://api.stripe.com matched
https://auth.internal matched
no live dependencies requiredproxymock replay --in-dir ./proxymock/recorded \
--test-against http://localhost:80804919 requests replayed
4917 identical
2 changed
POST /api/checkout
- "tax": 4.20
+ "tax": 4.2000000001That last diff is a real regression. Nobody wrote an assertion to catch it.
Promote a local recording into a CI job and every pull request replays real traffic before merge.
Response diffs are computed against what production actually returned, so there are no assertions to write or maintain.
Sensitive fields are masked at capture time, so recordings are safe to commit and share.
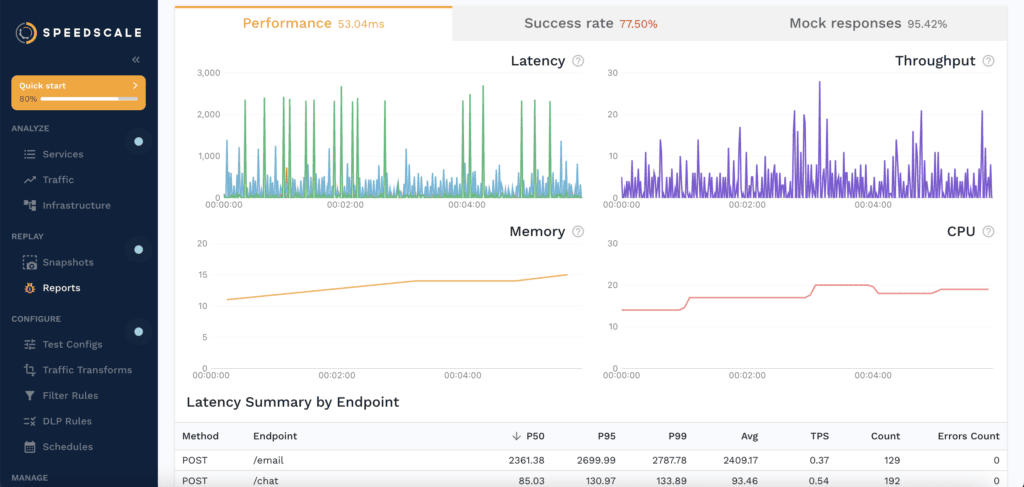
Latency is reported per endpoint at P50 through P99, so performance regressions surface in the same run.
Real traffic, captured once, reused everywhere.
proxymock runs on your laptop against a local process. No cluster, no operator, no sidecar. The same recordings run in CI when you are ready.
Postgres, MySQL, Redis, and gRPC are captured and mocked at the protocol level, so the dependencies your service actually talks to are covered.
Replay compares every response against what production actually returned. You do not write the assertions, and you do not maintain them.
Coding agents get a deterministic environment and a pass/fail signal from real traffic, instead of grading their own work against tests they wrote.
Install proxymock and get to a first record, mock, or replay in about ten minutes.